How we chose and implemented an effective model to generate embeddings in real-time.
Target has been exploring, leveraging, and releasing open source software for several years now, and we are seeing positive impact to how we work together already. In early 2021, our recommendations team started to consider real-time natural language input from guests, such as search queries, Instagram posts, and product reviews, because these signals can be useful for personalized product recommendations. We planned to generate representations of those guest inputs using the open source Bidirectional Encoder Representations from Transformers (BERT) model.
Background
BERT embeddings are used by many products across the Internet in a variety of recommendation tasks. User-generated content, such as search queries, product reviews, or social media feeds, as well as product descriptions, content banners, and offer descriptions, can be easily converted to embeddings to obtain a vector representation, or more simply, a large list of numbers. Similarly, we can generate an embedding representation of each product that Target sells, using its name and other text features. Then, explained in the simplest way, we can recommend relevant products by finding the nearest neighbors to the user-generated content in the embedding space.
Large deep neural networks such as BERT have about 100 million parameters, many layers of transformers, and require a lot of computing power to process.
Our team typically uses offline compute clusters for machine learning tasks, especially for large deep learning models. However, for this use case – generating embeddings of real-time text inputs – offloading the processing to compute clusters and exporting the embeddings back to serve clusters would not work well for us, as these clusters have high latency and high cost and may produce less relevant results because they would not be on-demand. With a requirement for real-time results, these large models could not meet our demanding speed and throughput requirements in production. We didn’t prioritize latency when using compute clusters because accuracy was our prime concern.
The production system for serving recommendations has challenging latency requirements. Our 95th percentile, or “p95,” latency requirement is 50 ms, meaning that the time between when our API is called and our recommendations are delivered must be less than 50 milliseconds for at least 95 out of 100 API calls. Even the standard BERT-Small model gives latency around 250 ms. When using large BERT models, the text embedding vectors can be as long as 768. This results in huge memory requirements. For example, generating embeddings for product titles of a product catalog with two million items requires approximately 25 GB of memory. This heavy requirement meant that standard BERT models could not meet our latency requirement and memory constraint.
Benchmark Metrics
For the purposes of this example, we will be focusing mainly on inference, throughput, and length of the embedding vector. Inference and throughput are most important for any language model to be considered for real-time product recommendations.
- Inference: the process of generating the embedding vector by running the input text through the model
- Latency: the median time it takes to serve one inference request. In this blog when we talk about latency, we are referring to 95th percentile
- Throughput: the number of inferences that can served in one second
- Embedding Vector: BERT models generate a unique vector for a given input text
Tooling
We are using the language models from the Huggingface Transformer library. We chose this library specifically for its PyTorch support, and as of this writing we are using PyTorch 1.7.1. We deployed these language models on an application layer built around the cloud computing services offered by Google Cloud Platform, specifically on Kubernetes.
TorchServe vs Microservice for Model Serving
We choose to deploy a single model in each microservice rather than deploying the model using TorchServe for the following reasons:
- We want to start with a simple, purely Python-based approach for scoring the BERT model. In our model serving scenario, each microservice serves only one single model.
- We want to start with a framework-agnostic approach as model serving should not be tied to any specific kind of model. Model server frameworks should be able to serve TensorFlow, PyTorch, `scikit-learn`, or any other Python library.
- We don't want developers to be constrained by any specific schema before sending the request to the model server. TorchServe and TensorFlow Serving require specific input and output formats.
- Our existing microservice framework already supports gRPC and has all the required support for common monitoring tools such as Grafana and Kibana, thereby avoiding the need to create any new tooling.
CPU vs GPU for Inference
Most of the open source language models available are trained on GPUs, making GPUs ideal for low latency inference use cases. However, we choose CPU for inference for the following reasons:
- All our real-time microservices run in Target's GCP Kubernetes which are CPU based.
- GPUs perform best when the requests are sent in batches. Implementing batching increases complexity, overhead, and latency. We don't have to batch the requests for CPU execution.
Final Choice of Language Model
Huggingface makes it easy to play with different language-based models like `Roberta`, `DistilBert`, `Albert`, and many more models released by Google. These are variations of BERT.
We tried different models like `Roberta` and `Albert`, and these models took more than 300 ms for inference. `DistilBert` is a smaller language model, trained from the supervision of BERT where token-type embeddings are removed and the rest of the architecture is identical while reducing the number of layers by a factor of two. The `DistilBert` model is recommended in technical blogs for low latency real-time inference, but even `DistilBert` could not satisfy our latency and throughput requirements. Despite giving us around 75 to 80 ms latency, CPU usage was quite heavy (around four to five CPUs).
We started with a baseline vanilla BERT model. We applied quantization, which involves improving the efficiency of deep learning computations through smaller representations of model weights. For example, we represented 32-bit floating-point weights as 8-bit integers. The p95 latency came out to be around 300 ms, which was unacceptable for real-time microservices.
Google recently released 24 pre-trained mini-BERT models to specifically address low latency and high throughput applications. We tried all 24 models and we found `BERT-Tiny` was best suited for our memory, latency, and throughput requirements. It has a hidden embedding size of 128 and 2 transformer layers. `BERT-Tiny` model gave us 25 to 50 ms p95 latency (with one CPU in production) and the Catalog Embedding file generated using the BERT-Tiny model was around 11 GB in memory. This was a huge improvement over other BERT models. `BERT-Tiny` model could easily handle 70 to 100 transactions per second (tps) per Kubernetes pod.
The following picture shows 24 different pre-trained BERT models released by Google.
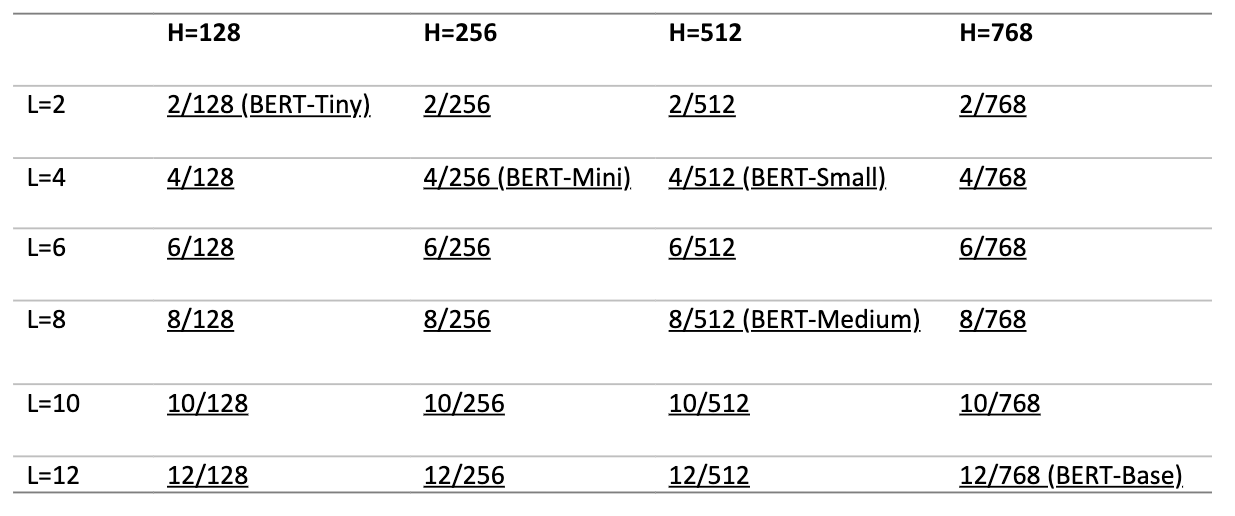
Comparison Metric #1: Latency
The next graph shows that `BERT-Tiny` has the lowest latency compared to other models. `BERT-Tiny` is highly suitable for low latency real-time applications.
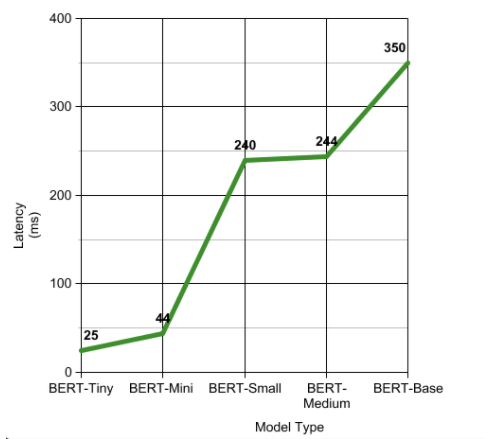
Comparison Metric #2: Average CPU Count
The next graph shows that baseline BERT model `BERT-Base` uses almost nine CPUs compared to `BERT-Tiny`, which uses two CPUs. The average CPU count matters in real-time applications where the Kubernetes pods have to autoscale when the real-time traffic increases and the new pods have to strive for CPU resources.
Comparison Metric #3: Embedding Vector Size
BERT model `BERT-Base` generates 768-length embedding vector compared to the smaller BERT model which generates 128 length embedding vector. Smaller embedding vectors have a lower memory footprint especially in applications such as generating embeddings for product titles of product catalog with two million items.
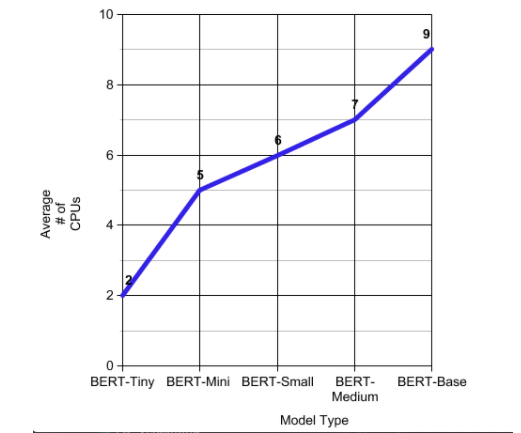
Comparison Metric #4: Throughput
The next table shows baseline BERT model `BERT-Base` has the lowest throughput compared to `BERT-Tiny`. This low throughput results in more pods serving the incoming requests. Smaller BERT models like `BERT-Tiny` can serve more requests with fewer pods.
Accuracy vs Performance
Going with a tinier version of the BERT model led to some degradation in the accuracy of recommendation models built using the embeddings. However, the use case considered in this scenario was real-time personalization and search, where latency is critical for the end user experience and has to be well below 100ms. Our team maintains the 95th percentile of response time less than 50ms. If we look at performance on standard benchmarks published by Google, the performance degradation of `BERT-Tiny` is within 20% of the standard BERT model.
Thus, `BERT-tiny` became our model of choice. Our next step is to fine-tune the model to Target-specific language. For example, we'll feed the model with Target.com search queries, product descriptions, product reviews, etc.
BERT Use Cases in Personalization
As mentioned earlier, BERT embeddings are used by many products across the Internet in a variety of recommendation tasks. We convert any user-generated content into embeddings to obtain a numerical vector representation of these inputs. In the simplest way, we can recommend similar products by finding the nearest neighbors in the embedding space. We used cosine similarity in nearest neighbor lookup for this task and it took around 5 to 10 ms. The total runtime along with other computations and lookups reached around 80 ms. By caching where appropriate, we were able to reduce the runtime to 75 ms.
In more complex use cases, we can pass the embeddings as input to other models trained for specific guest-facing placements such as Buy It Again (recurring purchase prediction), More to Consider (product recommendations), Based on Your Past Sessions (session-based recommendations), and so on. Ultimately, these embeddings help make the shopping experience easier and more personalized for our guests around the country. Better recommendations help to take the guesswork out of searching as guests shop on Target.com or via our app. We are looking forward to seeing what other benefits our BERT embeddings will bring to future work.
References