
The digital catalog team at Target is responsible for a collection of nearly 100 aggregated APIs to provide browse data for Target.com and mobile app platforms. In early 2019, we were just coming off a large backend migration which meant we would need to version a lot of these APIs. This was a huge effort for all teams involved in standing up and moving to new API versions. With the volume of APIs that needed testing, we needed a solution that would scale and allow our teams to move more quickly.
So that Spring we began the journey to create a self-service platform that would allow our internal web and apps team member clients to go faster. Dubbed “Redsky” by our team, this platform would give our clients the ability to experiment, improve turnaround time to market, and reduce complexity. Our goal was to help Target test new features and innovate more quickly with less upfront investment.
The Beginning
Our initial implementation leveraged the standard GraphQL POST interface to access a small schema that includes product, price, and promotion data. As the API began to roll out, we observed a few things that needed more consideration before we could move forward utilizing this for our platform.
The Learnings
We liked a lot of the features of GraphQL: strong typing, built-in documentation, a catalog of attributes, inherent support for aggregation, and the ability for clients to request exactly what they needed. However, there were some challenges: gaining the appropriate access to requisite Target data, learning a new type of integration, misuse that was proving hard to control, identifying performance problems, losing transparency, and monitoring. Examples of how others are approaching similar challenges include:
- The use of persistent queries can help control which queries are allowed to run as well as visibility to what the query is doing, such as is outlined in this post by Christoph Walter on the codecentric Blog. This approach solves the main concerns about unfettered access and the knowledge of what is being queried but introduces some misdirection when it comes to monitoring.
- Why GraphQL Performance Monitoring is Hard by Marc-André Giroux gives more details about monitoring challenges. These challenges have a common theme around the lack of knowledge about what exactly is being queried.
- Alan Cha of IBM authored A Principled Approach to GraphQL Query Cost Analysis. Alan details how to utilize query cost to try and solve issues related to the flexibility that GraphQL provides.
Most of the challenges listed above are a result of the POST nature of accessing GraphQL via HTTP. GraphQL does support a GET based request model where the client passes all the information as query parameters. While this is helpful, I believe there are issues with this approach – the most concerning being the size of the URL for large queries as discussed on Stack Overflow.
The Evolution
After doing the research, testing, and learning, we went back to the drawing board to try and come up with a solution that would work better for us. During these conversations we began to ask ourselves some questions:
- What if we were to flip-flop the problem and get the query upfront? This would protect us from unfettered access to data and give us visibility into how the query is performing.
- What if we could treat each query as an independent GET-based REST API and leverage our existing frameworks? This would allow us to monitor and manage each query individually by giving our support engineer the necessary information on when regressions were introduced, impacts from backend failures or slowdowns, and help in answering general questions related to the query.
This led us to client-managed REST APIs, leveraging GraphQL for defining the API and the runtime engine as outlined below.
The Outcome
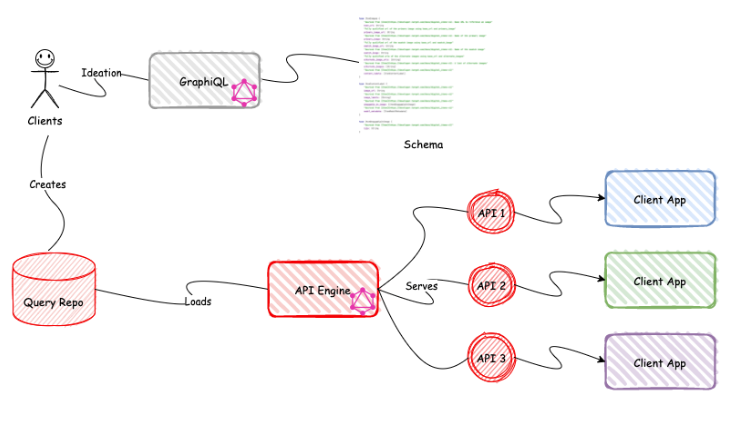
Clients
It all starts here. A client has an idea. They leverage the GraphiQL interface to interact with the schema and build out a working query. Once this query has been finalized, the client will submit the query to the query repo. This will initiate some automated checks with feedback as well as engage the engineer to do a final review before approving and making the query available in the API engine. Each client will be given their own namespace to allow for isolation, reuse of shared fragments, and personalized validation.
API Engine
This is where the magic happens. The API engine is responsible for realizing the query into a functioning REST-based API. Using the client namespace in conjunction with the query name the engine can serve an API. Any variable that the client has defined in the query will become a query parameter passed into the HTTP request. The shape of the response data will be the same as what the client saw during the ideation phase using GraphiQL.
The Unexpected
There were a few unexpected benefits from approaching the original problems the way we did.
With the introduction of a unified schema, our clients have drastically reduced their code base because of shared domain and logic. This has reduced the amount of client code that is required to execute on behalf of our guest, resulting in faster execution. Other benefits of reusing logic and components include less complexity, rework, confusion, and fewer issues.
Another benefit of a standard unified schema is the ability for our clients to generate strong types. The type generation tools also pull in useful information like data sources, comments, and even deprecations. These benefits combine to give our clients a richer user experience.
In this new model, our clients are telling us which fields they are using. This has helped us to remove unused fields, identify clients using specific fields, and simplify migration to new backend contracts. This is incredibly valuable API usage feedback enabling iterative improvements in subsequent versions of our APIs.
The Conclusion
Taking this time to reimagine our API platform has helped with Target’s success. We now have a platform to help our partners move faster, experiment more, and quickly identify impacts from upstream changes – all while providing a unified schema for all clients.
We have successfully versioned 200 unique APIs across thirty different clients, and over 250 schema types have been backed by more than 50 integrations. We have replaced close to 100 APIs and codebases, and now support the busiest days of the year in our stores with fewer resources and faster response times. Our users have called Redsky “absolutely brilliant” and shared that it “speeds us up, is easy, and better organizes so much data.” The platform has been described as a “complete turnaround in velocity for front ends.”
We’re proud of our progress so far and will continue to gather user feedback to help us iterate and continually improve our Redsky product. We hope this narration of our journey helps other engineers looking to build similar types of self-service platforms for their internal teams.