At the beginning of 2017...
... our engineering team embarked on a journey to facilitate rapid software delivery to Target stores to better enable innovation and more quickly respond to ever-evolving business needs. The destination seemed clear and simple, but we quickly discovered the path to get there was not – not well-defined for creating a distributed software runtime platform to scale to more than 1,800 edge locations. Along the way, however, we forged a path that will forever change how we build, deploy and manage software at Target.
Target stores sport a high-powered compute platform that enable the multi-channel retail experience and facilitate store operations. This platform runs applications that support the checkout workflow, in-store product search, team member services, IoT services, and so forth; all of which keep the store running and bring the best possible experience to our guests.
The greatest challenge teams faced with developing software for the stores was figuring out how to effectively build a continuous delivery pipeline to 1,800 deployment targets that was safe and expedient. Sprinkle in the fact that these deployment targets are truly edge locations, which have many factors that affect whether or not they are online and able to be deployed to, and you start to get the picture of the challenges we faced and wished to overcome.
The goal from the outset was to provide a platform for our store development teams, which would enable modern software development and continuous delivery practices. We aspired to be able to treat deployments to the stores with the same ease as our other compute offerings. In effect, we wanted the development and continuous delivery experience to be ubiquitous regardless of whether teams were deploying to the public cloud, Target's internal datacenters, or 1,800 store locations.
We decided early on to embrace containers as the underlying runtime in stores. We evaluated the major open source container platforms that were available at the time with the understanding that, in addition to needing to simply run workloads, we also need to provide higher-order infrastructure capabilities to truly enable the ubiquitous experience. Unlike in Target's datacenters and the public cloud, in the stores we don't have load balancers and robust networking infrastructure – our platform would need to provide all the infrastructure aspects we take for granted elsewhere.
We quickly landed on using Kubernetes as the foundation for our platform. Indeed, it won by a long shot by being able to best facilitate robust continuous delivery, higher-order infrastructure capabilities, and additionally supporting applications with configuration and secrets.
Because of the various challenges (power, weather, construction, etc) in running physical compute footprints in 1,800 disparate locations, the stores need to be effectively self-sufficient and can't rely on uninterruptible connection with Target data centers or cloud presence. This means the traditional compute models of clustering, failover, and high availability needed to be completely rethought for this project. In essence, we needed each store to act as its own mini-cloud, while presenting developers with the experience that it was really just one big fat cloud.
Enter Unimatrix...
Those familiar with Kubernetes might know a bit about the story of its origins at Google, where it was inspired by the Borg compute platform that faithfully supported the company's massive global scale. Prior to its launch, Kubernetes' internal project name was "Seven of Nine," borrowed from a character in the popular “Star Trek: Voyager” series. In Voyager, viewers were introduced to the Borg's organizational structure, which commanded multiple Borg "cubes" through a centralized apex known as a "unimatrix." The name was a suitable, immediate fit for our Target engineering team. We were inspired by the concept of the unimatrix to build a system that could command and control our fleet of Kubernetes "kubes."
We built our “Unimatrix” as the centralized apex system that would be the interface for deploying software to the stores. By interacting with Unimatrix, teams could affect changes across the entire fleet of Kubernetes clusters with a single command. Unimatrix was responsible for capturing the intended state for an application and distributing that state down to the store clusters. Through Unimatrix, each in-store Kubernetes cluster is able to act and operate as its own standalone mini-cloud, while appearing to developers to be a part of a broader collective.
To accommodate the central interface, we adopted the Kubernetes API and we present back the shared state across all the clusters in a single, unified view. Behind the scenes, we programmatically construct responses that merge the current known state of the disparate clusters to show what's currently running, what is the health of a pod in a given store, and so forth. To developers, talking to Unimatrix feels exactly the same as interacting with any other plain old Kubernetes clusters.
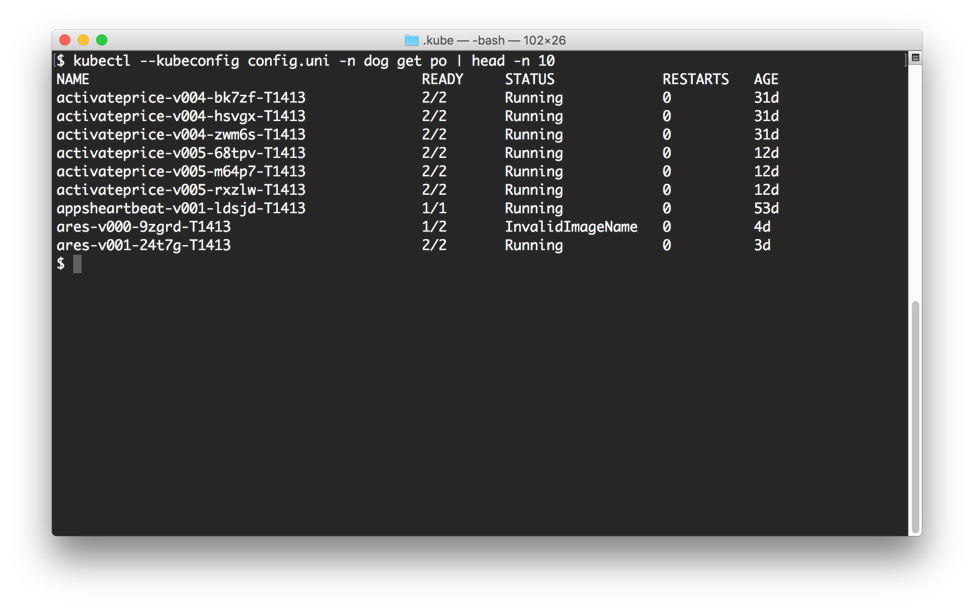
The various store development teams have different requirements in terms of what stores they deploy to first and what capabilities they are targeting. So, the problem of enabling continuous delivery to the stores wasn’t quite as simple as "give it to Unimatrix and a minute or two later you're deployed everywhere". We needed a way to differentiate stores with distinct capabilities so teams could build their pipelines specific to their needs.
Within Unimatrix, we implemented a facade for Kubernetes namespaces as a way of grouping stores by their unique facets. Some of these groupings include things like the types of registers that are in the stores, the regional markets these stores are in, whether the store has a certain IoT capabilities, and so forth. To date, Unimatrix exposes 27 different "namespaces" for the entire fleet, and teams can choose which group of stores they deploy to first, depending on what they're doing.
In our effort to provide safe, robust, high availability, and ubiquitous continuous delivery for our various runtimes, we adopted Spinnaker. As an early developer on Spinnaker, I helped build parts of the platform that would enable the complex delivery pipelines our teams would need to safely deploy across 1,800 stores, so it was a natural fit for Unimatrix. Because to Spinnaker, Unimatrix simply looks just like a Kubernetes cluster, we were able to plug it in and instantly see applications' health and deployed state across the entire fleet of stores.
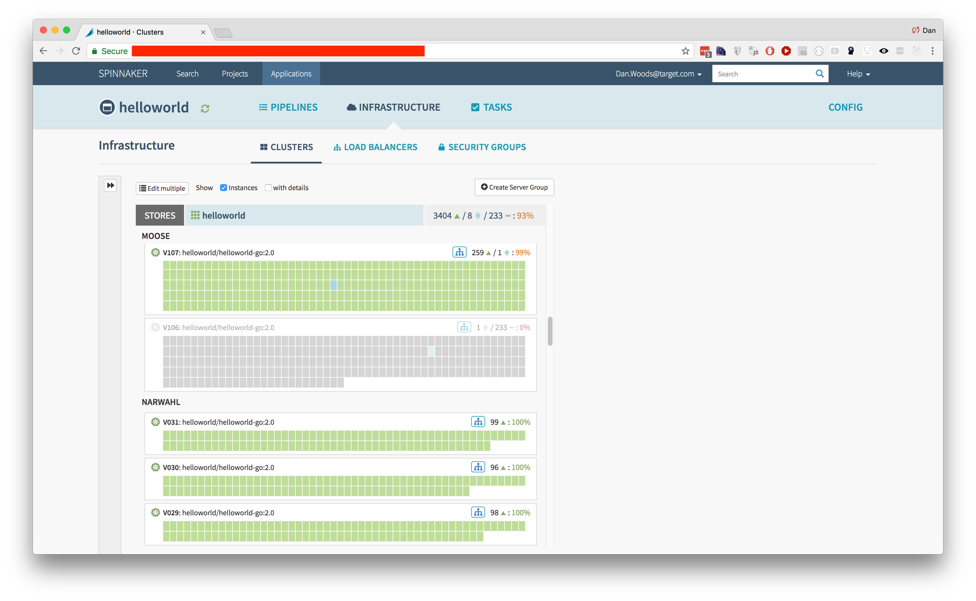
By our 2017 peak season, we had multiple teams deploying production workloads to several hundred stores via Unimatrix. By early 2018, we had Unimatrix rolled out to all store locations, and today we enable hundreds of zero-downtime production deployments per week across the collective. We continue to innovate with software and technology in our stores with unprecedented velocity, and as we forge ahead, Unimatrix will serve as the foundation for those efforts.