
At Target we’re always evolving our business to meet the needs of our guests and team members — which means we’re also always evolving how we build technology. But even though technologists work in an environment that is rapidly changing and advancing, it can often take a long time (sometimes even years) to get to a point where we can retire legacy systems. I wanted to dig into why and explore shimming as a solution to help.
Observation: Moving Data Sources Is Hard
Any coexistence period where old legacy systems and modernized solutions need to act in harmony can be challenging. While it’s relatively easy to build a new greenfield system from scratch, including all the engineering bells and whistles, trying to manage a rollout from the legacy system to the modern solution in your direct control is made more complicated when you are dealing with integrated systems — especially when you’re the data provider for other systems as well.
Complexities to consider:
- Maintaining completeness of data. Most implementations of new systems are not a “big bang” overnight and as such, modern systems may not have 100% of the data on day one. This could be dragged out over months or years based on stakeholders’ readiness.
- Redefining schemas of what new data sources look like. New systems are an exciting time to make things better but changing data formats or relationships can have a ripple effect on other systems and business functions.
- Changing strategies in system integrations. This has certainly been true for us at Target! Point to point integrations and direct database access as a strategy serves a purpose in mainframe and monolith heydays, however this has now been replaced with a services-first modular architecture.
- Motivating consuming systems to make the switch. They might not be eager to if they’re on a journey to modernize, as well. Who wants to work on the old codebase if it is going away?!
- Timing assumptions. Even if teams commit to them in good faith, timelines are almost always wrong.
So… what can you do to effectively transition through an ever-shifting landscape of systems, deliverables, and data needs without upending all the business functions that depend on your data?
Suggestion: Shimming
While not always the right choice, shimming can be a great solution in some scenarios.
A shim is a temporary patch of data that is used during that coexistence period, enabling you to create a “whole” data set rather than two separate sets of data. Shims serve two primary purposes:
- Shim back — replicating data from a modern/future system back into a legacy/old data source. The goal is to keep old customers “whole.”
- Shim forward — replicating data from a legacy/old system forward into a modern/future data source. The goal is to get new data source “whole” so customers can move over as quickly as possible.
When a rollout approach gradually requires a move from a 100% shim forward toward 100% shim back over time, a bi-directional shim of both shim back and shim forward might be needed to prevent duplicate transactions in any one data source.
Building shims takes time – so much time in fact that it might be tempting to think it would be easier to simply “move fast” so it can be skipped entirely. While tempting, in a technology landscape of Target’s size and scale, skipping shims is simply not realistic when considering the amount of technical debt being dealt with.
That doesn’t mean shims are always the right choice. We were able to embrace shims as a tool because we set parameters around when we use them.
To Shim Or Not To Shim?
Here are a few examples based on common considerations that we used to decide if we should build shims or not.
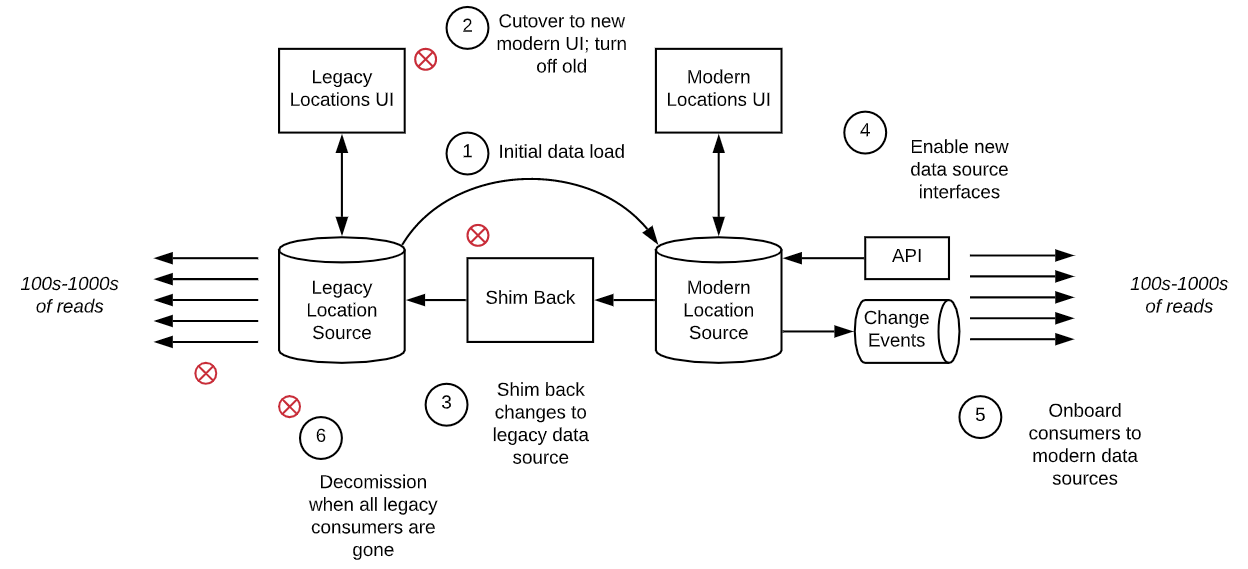
Location Master Data
This data defines all Target locations such as stores, distribution centers and headquarters locations, including address, hours of operation, and capabilities. The legacy source resides in DB2 in our mainframe environment. The modern source would be service enabled via APIs and change event kafka topics.
The choice of whether or not to use shims is a big one. Here are some of the things Target tech takes into consideration when deciding:
| CONSIDERATION | ANSWER | SUPPORTS SHIMMING? |
| Can we significantly accelerate adoption of the new data source if we shim forward? | No, the conversion to modern can be done within a day; there is no extended rollout period. | No |
| Do we create more problems than do good if we shim back? | No, the mapping is pretty straightforward. | Yes |
| How long will this actually need to last? | It will take years to modernize all the legacy customers. | Yes |
| How many consumers will be impacted if we don’t shim back? | 100s of apps, 1000s of programs and most of the access is hardcoded SQL queries and joins. | Yes |
CONCLUSION: SHIM BACK
WHY: Due to the vast number of essentially hardcoded legacy consumers, we did not think it was a good enterprise investment to require them all to change and it would be better to have the team that owns location to shim back to the legacy data source, even with that shim needing to last for a very long time. There was no need to shim forward since the rollout was trivial in terms of timing.
PATTERN APPLIED:
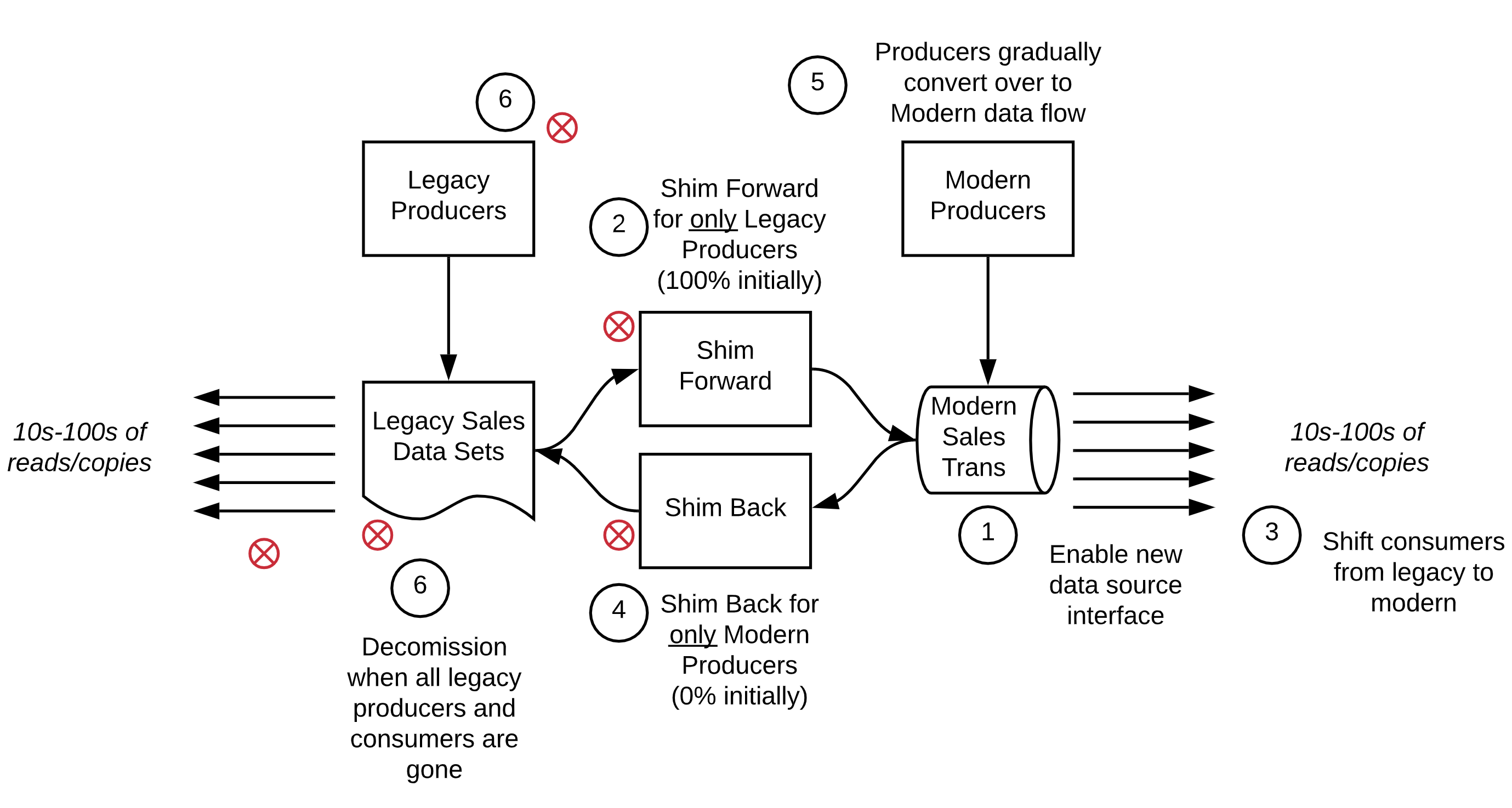
Sales Transactions
Sales transactions are a critical source of information for financial reporting, settlement with guest tenders, business analytics, and other operational activities such as fraud detection. The legacy data source is a set of mainframe data sets. The modern source would be service enabled primarily via a sales transactions Kafka topic.
| CONSIDERATION | ANSWER | SUPPORTS SHIMMING? |
| How many consumers will be impacted if we don’t shim back? | 10s of apps, 100s of programs. Most access involves reading or replicating data sets. | Yes |
| Do we create more problems than do good if we shim back? | No, but we will need to figure out how to map things correctly as we look to improve the future state schema/format. | Yes, but the details are extremely important for the design |
| Can we significantly accelerate adoption of the new data source if we shim forward? | Yes! Not having a full set of data in the modern source would be a roadblock for many consumers. | Yes |
| How long will this actually need to last? | Years. Migrating upstream systems to the modern sales data flow and moving legacy consumers will take a really long time. | Yes |
CONCLUSION: BI-DIRECTIONAL SHIM
WHY: Sales data is critical to get right, and we didn’t want to risk multiple consumers trying to keep things “whole” independently. We also wanted to equally support legacy consumers and modern consumers as quickly as possible.
PATTERN APPLIED:
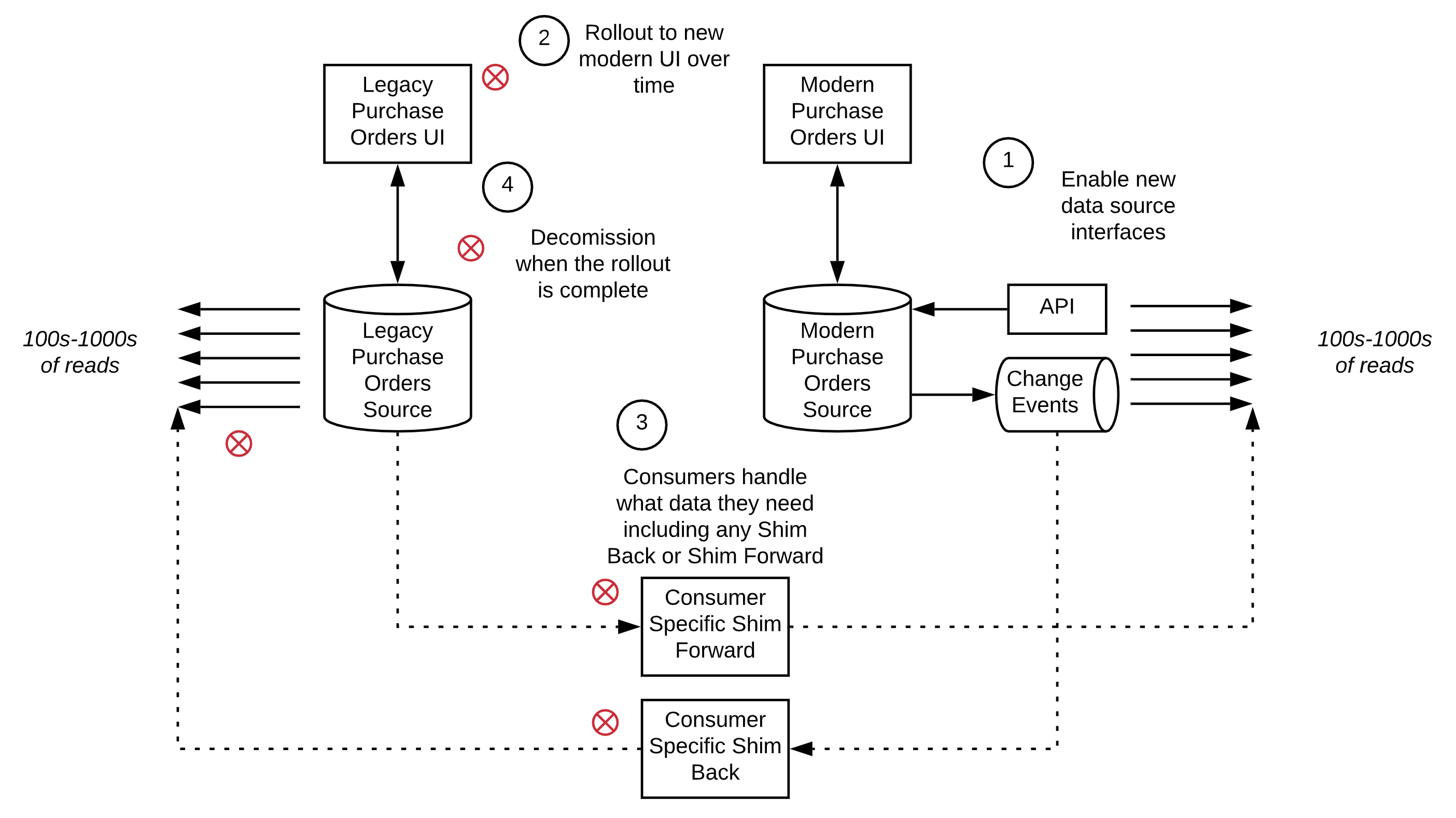
Purchase Order Transactions
These transactions represent purchases from vendors for products that usually move through our supply chain such as toilet paper, snack foods, and electronics. The legacy source resides in DB2 in our mainframe environment. The modern source would be service enabled via APIs and change event Kafka topics.
| CONSIDERATION | ANSWER | SUPPORTS SHIMMING? |
| How many consumers will be impacted if we don’t shim back? | <10 apps, 10-100s of programs. Most access involves reading or replicating data sets. | Maybe |
| Do we create more problems than do good if we shim back? | Yes. If we shimmed back we would need to deal with: 1) consumers that only need to execute on the legacy transactions and would now need to filter; 2) Modifying the Legacy UIs to prevent users from adjusting modern transactions; 3) New formats and constructs would make it extremely difficult to map modern into legacy sources. | No |
| Can we significantly accelerate adoption of the new data source if we shim forward? | Yes, but no. A few consumers need all the data during coexistence, but others only wanted one or the other. Also, until rollout is complete, it doesn’t really matter if consumers are still reading the legacy data since it still needs to exist for our business users, anyway. | No |
| How long will this actually need to last? | Years. Business and vendor partner adoption will take some time. | No (considering above) |
CONCLUSION: NO SHIM
WHY: The impacts of Shim Back or Shim Forward were not all positive, and as such, we opted to let each consumer determine what their needs were and act accordingly.
PATTERN APPLIED:
In Conclusion
Although we were initially resistant to adopt shims overall, applying a construct to help us be smart about where to implement them made us effective. Using these shim tactics – and aligning people to build and operate them – was foundational to helping Target tech progress on our modernization journey while maintaining the most critical legacy business functionality.
There is a trap, however, in getting too comfortable with your shims — keep in mind that legacy consumers may have no real reason to migrate off. If they don’t migrate, then you’ll face additional costs related to maintaining and supporting two equivalent data sources longer than necessary. Strong and consistent leadership as well as measurement and tracking progress are crucial to ensure your use of shims is successful and without long-term technology debt.