Introduction
In today's rapidly evolving digital landscape, personalization has become a crucial aspect of providing exceptional user experiences. Customers expect tailored recommendations and relevant content that meets their unique needs and preferences. However, delivering real-time personalization at a scale can be a challenging task, especially when dealing with monolithic architectures.
To overcome these challenges, many organizations are turning to microservices as a solution. Microservices architecture allows for breaking a large application down into smaller, more manageable components that can be developed, tested, and deployed independently. This approach enables organizations to respond more quickly to changing business requirements, scale applications more effectively, and provide better fault tolerance and resilience.
The Personalization team (PRZ) at Target is responsible for creating personalized experiences for Target's guests across various channels, including the website, mobile app, and in store. In 2022, PRZ generated more than four billion dollars in attributable demand and served 169 billion recommendations to guests. This article will explore how PRZ has accomplished this using the microservices architecture.
Evolution of Personalization at Target
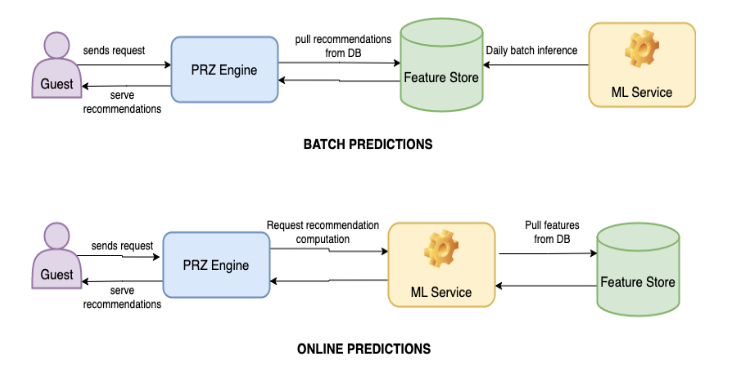
PRZ initially released our recommendation pipelines in 2014, commonly called PRZ 1.0, which centered on producing batch predictions.
Batch Prediction:
All predictions are generated in bulk and produced at specific intervals, such as daily. This method is widely used in areas such as collaborative filtering and content-based recommendations, particularly when the input space is limited, and the number of potential inputs can be determined. For example, we used batch prediction to generate product recommendations that are based on popular customer searches, product views, purchases, and current trending items.
Batch prediction has many limitations. More than half of the visitors to Target.com are new users or are not logged in. Because these visitors are new, there are no precomputed recommendations personalized to them. By the time the next batch of recommendations is generated, these visitors might have already left without making a purchase because they did not find anything relevant to them. In such cases, batch predictions lead to decreases in user experience, which is tightly coupled with user engagement and retention.
In 2017, PRZ introduced PRZ 2.0, which involved the implementation of real-time online predictions using the microservices architecture.
Online prediction:
Instead of generating predictions before requests arrive, predictions are generated after requests arrive by collecting users’ activities in real-time. When a new user visit Target.com, instead of suggesting generic items, we can now show them items based on their activities. For example, if they have looked at a keyboard and a computer monitor, they are likely looking at work-from-home setups and we would recommend relevant items like HDMI cables or monitor mounts. This increases user engagement and retention since the recommendations are tailored to individual users' interests and preferences.
PRZ has traditionally utilized Java microservices for deploying algorithms in production. In 2019, significant advancements were made in refining recommendation algorithms and enhancing the architecture. These developments gave rise to the Python microservices architecture, which empowered Data Scientists to create and deploy their own microservices using Python and serve recommendations online more efficiently without requiring the assistance of an engineer. Some of the other reasons why Python microservices were needed are:
- The Python ecosystem for deep learning is mature and offers a comprehensive set of tools for creating and productionizing deep learning models with libraries such as Tensorflow, PyTorch and Keras. In contrast, Java’s ecosystem for deep learning is still developing with newer libraries such as Deeplearning4j and DL4J lacks the same level of maturity and breadth as the Python ecosystem.
- Python has a simple and easy-to-learn syntax, making it a popular choice for developers to quickly prototype and build microservices.
- Python’s large community and abundance of resources are beneficial, but the community’s welcoming nature towards new developers where anyone can easily find answers to questions, find libraries and frameworks that meets their needs, and get help when they need it, makes it a compelling choice for microservices development.
- Python microservices framework accelerates the process of converting a model into a production-ready state.
As of early 2023, there are now dozens of microservices in Python and Java that are actively running in production.
PRZ's microservices architecture
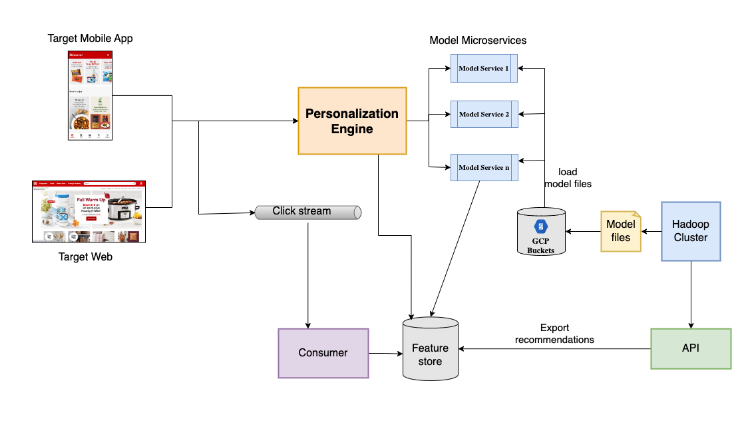
The Python microservices framework implements gRPC, an efficient remote procedure call framework developed by Google, to create a microservices architecture. The models are trained and developed in Target’s Hadoop cluster or offline methods, and then uploaded to the Google Cloud Platform (GCP) where they are loaded into the gRPC server's memory. These gRPC services are integrated with click stream data, the Target catalog, and other relevant information stored in the same feature store, which is loaded through an API. To access the click stream data captured from Target's website and mobile app, the personalization engine serves as the gRPC client and sends requests to the model services. This data is consumed and stored in our feature store for efficient retrieval and is also used by the gRPC models. Personalized recommendations are generated by scoring and sorting items using the models.
Use cases and applications
Microservices are used in many ways to enable real-time data processing and decision making. Examples of these use cases include:
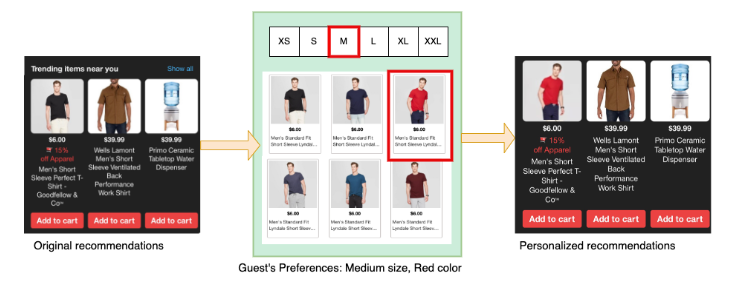
- Real-time aggregation: Some recommendation services infer a guest's relative preferences for attributes such as brand, color, flavor, and size to enhance product recommendations on apps and websites. This is achieved by real-time aggregation of all guests' digital interactions including the most recent ones as well as their store sales going back many months, to get an understanding of guests’ preferences of specific attributes when they shop for items.
- Real-time scoring of deep learning models: Some models employ deep learning models such as graph neural networks to predict items that a user may be interested in purchasing based on their recent activities. For example, we have a model that gives recommendations based on multiple items in real-time i.e., if a guest adds milk to their cart, we recommend other grocery items. Next, when the guest adds eggs to their cart, we recommend breakfast items. If the next item added to cart is sugar, we recommend baking supplies.

- Real-time filtering and re-ranking: Frequently, we have a desire to re-rank product recommendations and enhance them to satisfy various goals, such as relevance, profitability, shipping cost, availability, or the preferences of individual guests. Microservices offer an ideal platform for carrying out this type of real-time decision-making.
- Real-time features & bandits: Microservices are a powerful tool used to create and deliver real-time guest features such as category clicks and deal preferences. They are also employed to implement advanced algorithms, such as bandits, that enhance recommendation systems.
Performance
Latency matters, especially for user-facing applications. In 2009, Google’s experiments proved that increasing web search latency from 100 to 400 milliseconds reduces the daily number of searches per user by 0.2% to 0.6%. In 2019, Booking.com found that an increase of 30% in latency cost about 0.5% in conversion rates — “a relevant cost for our business.”
No matter how great your Machine Learning models are, if they take just milliseconds too long to make predictions, users are going to click on something else.
The performance of microservices can vary depending on several factors, including the complexity of the underlying algorithms and the volume and velocity of the data being processed. All the current microservice implementations that are in production right now are meeting our Service Level Agreement (SLA) requirements of 50ms latency for an average throughput of 100tps.
We have observed that if the service in question is expected to handle a moderate level of traffic, with a throughput rate of around 100 transactions per second, Python microservices would be the optimal choice. However, if the expected traffic volume is significantly higher, with a throughput rate in the thousands of transactions per second, utilizing Java microservices would be a more suitable option.
Conclusion
Looking towards the future, PRZ will continue to focus on enhancing the personalization experience for Target's guests. One area of focus is incorporating more advanced machine learning models and deep learning techniques to further improve the personalization algorithms. Deep learning models can process large amounts of complex data and uncover hidden patterns and relationships that traditional machine learning algorithms may miss. Another area of focus for PRZ is improving the scalability and fault tolerance of the microservices architecture. This includes optimizing the resource allocation and load balancing mechanisms to ensure that the system can handle the growing volume of requests and traffic.
RELATED POSTS
Using BERT Model to Generate Real-time Embeddings
By Pushkar Chennu and Amit Pande, March 23, 2022
How we chose and implemented an effective model to generate embeddings in real-time. Target has been exploring, leveraging, and releasing open source software for several years now, and we are seeing positive impact to how we work together already. In early 2021, our recommendations team started to consider real-time natural language input from guests, such as search queries, Instagram posts, and product reviews, because these signals can be useful for personalized product recommendations. We planned to generate representations of those guest inputs using the open source Bidirectional Encoder Representations from Transformers (BERT) model.
Spring Boot Service-to-Service Communication
By Jeffrey Bursik and Pruthvi Dintakurthi, December 18, 2018
This post will walk through our implementation of Spring Feign Client, our learnings, and how Spring Feign Client has helped manage our inner-service communication while reducing the amount of development time.