
With the release of ChatGPT and other Generative AI tools in the fall of 2022, we all experienced what happened the first time AI was put in the hands of the general public - when they tried it, it felt like magic. Even to grizzled and experienced data scientists, it felt like everything changed.
While Generative AI will continue to dominate the headlines, it is only one small part of the world of machine learning. It’s a new tool to put in the hands of our scientists, engineers, and business owners, but there is still enormous value yet to be realized in the other areas of machine learning.
Well-orchestrated integrations of machine learning in core retail applications allow teams to scale their implementations of decision modeling to great success. Here at Target, we’re no strangers to AI and machine learning, and have spent several years leveraging this technology to solve large-scale challenges like demand forecasting and inventory planning. We also use AI to help decide how much – and how often – to mark down prices when it’s clearance time, and to help personalize the digital shopping experience by making recommendations to our online guests. We can see this approach already paying off for Target in our e-commerce, merchandising and end-of season clearance, and inventory management. And, although nascent, we have seen incredible results when we apply machine learning to a typical problem that vexes all brick-and-mortar retailers – out-of-stock products.
Setting the Stage
When we present both internally at Target and at external conferences, it’s typical to show photographs like this one of gorgeous stores with shelves full of merchandise. Oftentimes, our stores do look like this, which is a delight to our guests.

However, the reality is much more complex, and sometimes items end up out of stock.
Measuring out of stock or on shelf availability as a metric is commonplace in the industry. However, these are usually measured systematically, which means your systems have to know already that the on-hand quantity is zero. When we performed recent physical audits of our inventory, which we do once a year for all items in every store with some items counted more frequently, we discovered that half of the out-of-stocks were unknown to our systems. In other words, the system believes there is inventory, when there is not. It was hard, but imperative, that we accept that our out-of-stock metric was under-reported by half.
How Does this Happen?
Retailers know that maintaining 100% accuracy regarding every unit of more than 100,000 SKUs is impossible. Shipping and receiving mistakes, theft, misplaced items, and system glitches all conspire to skew on hand quantities – also known as “shrink.” When the system thinks there are still 10 soccer balls on hand, it does not trigger replenishment and eventually sales for soccer balls go to zero in the store because they’re out of stock and the system doesn’t know it.
The AI Approach
AI is well-positioned to significantly help detect and correct unknown out-of-stocks. One approach to this that we tested in several stores is to use shelf-edge cameras and computer vision: image streaming and object detection. Our very talented computer vision team at Target built and tested this ourselves. We even integrated this approach into one of our store team member apps for task management. However, there are not only considerable hardware costs and ongoing hardware maintenance involved in outfitting such large stores, but some of the implementations are intrusive to our guest experience.
Throughout the last 15 months, we have worked across the enterprise to unlock a new capability where we infer inventory anomalies and systematically correct them. Our assortment is complex and that makes this problem challenging to solve.
We are developing AI capabilities that infer inventory inaccuracies from analyzing the underlying data patterns and then systematically correcting them. We use an ensemble of AI models and each one of those models is specifically tuned to identify the patterns that are unique to that product category and then they make predictions of unknown out-of-stocks. We then pass these inferences to our inventory accounting systems that then make automatic adjustments to fix the unknown out of stock and trigger replenishment back into our stores.
We designed this new system, the Inventory Ledger, to increase the impact of machine learning through integration into core retail applications. Inventory data is the life blood for all retailers, so interfacing with inventory systems can be fraught with risk. The integration must be well-designed and well-considered.
We want to share how we have designed that integration with these needs and risks in mind.
What is the Inventory Ledger?
Put simply, the Inventory Ledger was built to report any change of inventory position or disposition for every item at every location at Target. When you think about the fact that Target has nearly 2,000 stores across the United States, that is a lot of inventory to keep track of. We also track inventory that has multiple locations within a single store – think of batteries for example.
Before we had the Ledger, we simply collected and stored information on the current state, but we were unable to easily answer questions about why or how the stock got to that level. Frankly, we got tired of doing the research when people asked us that question. So, like many great inventions, the Inventory Ledger was created out of the desire to make life just a little bit easier.
The Ledger essentially provides a journal of all inventory changes including guest sales, replenishment, items put away in the back room, order fulfillment, and more. It paints the full picture of our inventory for a given item in a specific store. It’s transaction aware, understanding the context in which inventory transactions are being done, is able to process transactions out of order, recover from upstream issues, and is able to detect and resolve anomalies such as duplicate events.
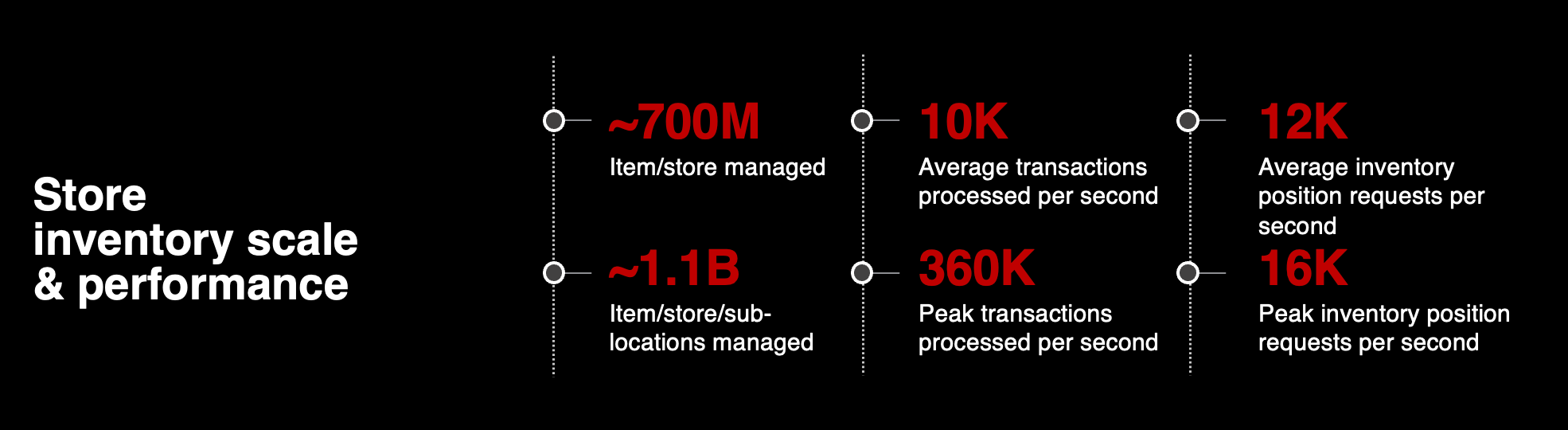
The Ledger is a highly performant system built to operate at Target’s nationwide scale. At peak loads, we process up to 360,000 inventory transactions per second. We serve up as many as 16,000 requests for inventory positions per second, and we are set up to scale far beyond that to meet growing demand.
Since this was the first time we intended to make inventory adjustments based on inferences, we had to build an architecture that could be flexible and resilient, all while protecting the accuracy and performance of the Ledger. As the work came together, we realized there were multiple initiatives being tested at Target using different machine learning models, shelf weight, light sensors, and shelf-edge cameras. Sometimes it felt like everybody at Target had a new idea or method for solving this problem. We agreed to continue to test and evolve all of these methods using data to drive decisions on how to proceed and develop an architecture that could support this type of learning and experimentation.
The Architecture
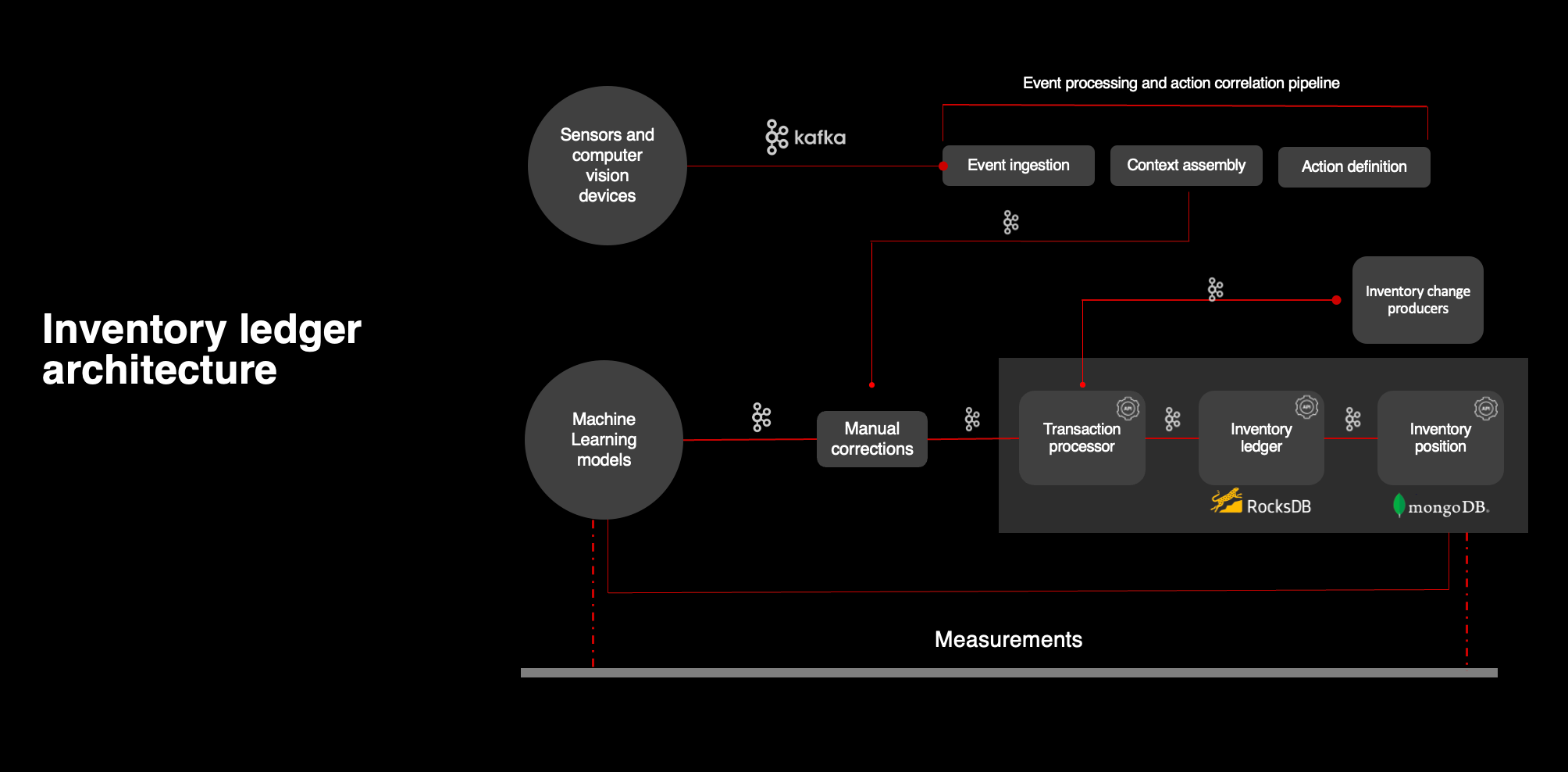
Let’s take a high-level view of the underlying architecture. As is typical at Target, this is an event-driven, stateless, and polyglot architecture. We listen to inventory transactions or “events,” we write them to the Ledger, we update the overall inventory position for every item at every location across Target, and we respond to requests for inventory position as well as historical context of how we arrived at that position all in real time. A system at this scale requires some cutting-edge engineering. We have 20 instances of RocksDB databases that compute our inventory state in real time. We even had to develop a custom sharding scheme to partition the traffic across our Mongo database instances because the native sharding scheme didn’t work at our scale.
Importantly, for this effort we needed the architecture to react to inferences from a variety of sources while insulating and protecting from an unpredictable result that could have been possible in these early experiments. We also needed to accommodate the batchy nature of updates coming from these inferences. To conserve battery life, sensors and cameras send us corrections just once a day. Those inferences flowed through the event processing and action correlation pipeline. This allowed us to test any sensor that could be deployed to the store.
Machine learning models also send us corrections once a day. We did not want to do interventions for the same item at the same store too frequently, as we wanted to see how the intervention assisted in correction before taking any additional action.
At first, all the inferences triggered manual tasks for a store team member to verify and correct the inventory. Humans were able to check that the suggested changes were correct and ensured we weren’t further eroding our inventory accuracy. Because there were multiple inferences being tested, we needed to build a solution that would allow for many tests to be run in parallel and give us unbiased results.
We had many competing signal types with a lot of pride of ownership from across the teams. To accomplish this, we worked with a separate team outside of each of our areas to help us define and perform strategy agnostic measurements. These measurements were performed repeatedly, comparing our inventory accuracy before and after. We used that data to make decisions on how to proceed and we quickly realized that continuous measurement was going to be an ongoing need as the models evolved. As we gained confidence in our signal types, we learned we needed a way to systematically decide which method was the best one for the correction. So, we developed an arbitration engine to process the correction suggestions from the multiple signal types. Only one of those recommendations for an item wins, and that recommendation is then passed along for correction. As the volume of these correction suggestions grew, human intervention could not operationally scale, so we moved to automated corrections, building a systematic way to act on the winning suggestion from the arbitration engine.
We learned that having a team define and perform measurements separate from the team developing the solutions allowed for a discrete and unbiased focus on measurement, enabling easier decision making. Our architecture effectively decoupled inventory systems from the methods of detecting inaccuracies, allowing us to test new methods in parallel as well as adopt and coexist with an ensemble of algorithms, each specializing in a specific set of products. Having a collection of algorithms is proving to be critical given the large variety of products that we sell at our stores.
Ultimately, we eliminated sensors and cameras as a mechanism for detection. While they were effective, they proved to be costly and difficult to maintain at our scale. Inventory corrections made by the models have resulted in substantial sales lift for the products that otherwise would not have been available for guests to purchase, and the models continue to learn and improve.
Here’s How it Works
To find unknown out-of-stocks and correct them, we need to be able to find patterns in our underlying data from product, sales, Inventory Ledger, and replenishment that tell us that an unknown out-of-stock exists. However, these patterns can be as complex and varied as Target’s assortment and operations. In addition, patterns may be unique to each category. For example, shampoos can regularly change sizes with attached promotional product samples while soccer balls see great variation in sales across the seasons. This means that what works in essentials may not work in sporting goods.
Machine learning algorithms are specifically designed to find solutions that do generalize across the assortment, finding complex patterns in real time within Target’s high volume, multi-dimensional data sets. While sometimes not telling us exactly why, they are able to tell us if an unknown out-of-stock is happening so we can detect it with high confidence and automatically correct it without team member intervention.
Our algorithms are trained on millions of examples of unknown out-of-stocks from the past. We use labeled data, generated by standard, in-store activities. Because we are opportunistically using this data as our labeled training data, it was not designed for ML use and is occasionally biased. We use domain acumen and data sanitization techniques to create millions of rows of trustworthy training data. One easy example of this is that we do not want to train a model on December training data for application in the summer. The retail patterns of purchase and replenishment are too different to get high precision and recall in both temporal epochs.
We use this training data to extract thousands of simple pattern detectors, with each one defining a unique condition that predicts an unknown out-of-stock. Most of the time this is a decision tree, identifying a combination of sales, in-store movements, and supply chain features to correctly predict unknown out of stocks. Importantly, these algorithms work at Target scale, which means across Target’s assortment, including apparel, accessories, beauty, food and beverage.
One of these pattern detectors is often not accurate enough by itself, but machine learning supercharges this by optimally combining thousands of these detectors and finding patterns among the pattern detectors. Through the use of gradient boosted trees and neural networks, we can apply a model across many different domains. This is not a “one-model to rule them all” scenario. We employ thousands of models across the assortment, and they frequently overlap with each other. One model may be better at finding errors associated with missed sales while another is tuned for shelf capacity variations. We use an ensemble model to combine many smaller models, managing conflicts and providing a single output for all models.
Our ensemble modeling framework allows us to build a suite of models with different specialties. We create specialized models in two main ways. The first is through domain restriction. We may train a model on yogurt sales separate from soccer balls because we know these products move through our supply chain and stores differently. By focusing the model on finding patterns within a domain, we can achieve desirable precision and recall. The second method of creating specialized models is through feature restrictions. In partnership with our business process analysts, we identify that certain process defects have a digital signature in our Inventory Ledger data. The digital signature alone is not enough to get the precision we require. But if we begin by filtering to that digital signature and then train a model, we can see precision rise above our acceptance criteria threshold.
When our algorithm does its daily inspection of an item and its inventory activity, if enough of the pattern detectors ignite across one or many different models, our ensemble algorithm can say with very high confidence that the item is an unknown out-of-stock.
We integrate with the Inventory Ledger, passing our corrections to Ledger to adjust the on-hand quantity to zero. Then, our regular replenishment can take over. The zero on-hand quantity triggers replenishment, ensuring that the product is again available to our guests. By validating the accuracy of these algorithms in-store, we’ve measured their power and precision first-hand, giving us the confidence we need across the enterprise to trust these methods and deploy these algorithms across almost every product category across all our stores.
The Future of AI-fueled Inventory Management at Target
With plenty of variety in detection signals, the ensemble model approach allows us to develop a comprehensive probability of any given item being out of stock. When the probability crosses a certain threshold, we automatically intervene to update our systems, thus triggering replenishment and pleasing our guests. We can configure this threshold on the back end, to customize it depending on the product and category. Through the use of an ensemble of models along with the careful integration with our Inventory Ledger, we know that we are making an impact on our unknown out-of-stocks, we know that we have fuller shelves as a result, and we know that we are delighting our guests which is the whole reason we are here in the first place.