
Inclusivity is a key part of a healthy engineering culture. To be inclusive, we must identify and remove the unnecessary barriers that inhibit good experiences. Crafting a productive Python developer experience is challenging, especially the process of setting it up. The absence of a rock-solid onboarding process creates poor experience for many developers, even those familiar with the many forms of Python tooling. We found that using Make helps alleviate these barriers, allowing developers to rely on common tools that automate the preparation of a Python development environment. This expedites entry to a productive test-driven development cycle that produces high-quality software.
At a high-level, I will review the pains I experienced and have observed in the last few years as an experienced developer working in Python for the first time since 2005. I’ll talk about barriers to productivity in a Python codebase and how I’ve overcome them using that venerable tool: Make.
The intended audience for this article is teams using Python who are struggling with remembering commands, configuring development environments, and ensuring a consistent developer experience across many codebases.
We’ve released a companion example project using the solutions presented herein at https://github.com/target/make-python-devex. We've iterated on this since 2021, made major improvements in 2022 when this article originated as an internal presentation, and released this open source project in early 2024.
About Me
I’m a Lead AI Engineer in Target Tech’s Data Sciences group. I’ve been a developer for more than 20 years. I started out professionally in PHP before moving to Ruby, Java, and a proprietary XML-based language for work, then spent many years working in Scala while picking up POSIX shell, Rust and Groovy along the way. I returned to Scala for a while when I first came to Target. I find myself working primarily in Python since January 2021, my first since using Python in 2005 for a distributed computing project in college.
I focus a lot on developer experience, especially on automation and onboarding. I believe that delightful tools and conscientious practices enable building reliable software.
The Problem and a Diagnosis Leading to a Remedy
Like much of the software industry, Target uses Python primarily for data science. In 2024, the Python ecosystem is the default choice for end-user developers to build new data analysis and machine learning applications, including AI model training pipelines.
However, my team found some frustration with the Python ecosystem. We want to clearly identify the problems, understand what causes them, and how we might address those causes.
I’m a huge fan of addressing problems through a problem-diagnosis-remedy approach consistent with medical and other scientific approaches to problem solving. Tbl. 1 provides an extreme summarization of this entire article in a format fit for quick readers, especially executives.
| Problem | Diagnosis | Remedy |
| Poor developer experience slows development; getting Python DevEx right is hard | Python project definitions leave too much undefined | Standardized Makefile-based system for Python dev |
Table 1: This article, summarized for executives
I maintain a template for problem, diagnosis, remedy proposals in this format, including a version of it suitable for use with Architecture Decision Records.
Problems
Working with my teams of engineers and data scientists, we encountered these questions, the variable answers to which were our core problems:
- What Python version should I use for development?
- What Python version will be used for production?
- How do I install Python at a specific version?
- How do I ensure that my project works on a diverse development and production installation base?
- How do I install dependencies?
If you’re getting a tingling feeling that all of this could be written down somewhere, you’re getting the same feeling I felt within the first week of working in Python for the first time in more than 15 years.
This problem reduces to this particular question:
Which Python?
Diagnosis
We found these reasons why Which Python? is such a hard question to answer:
- Unreliable OS-provided packages, mismatch with production environment
- Too much choice in non-OS packages leads to inconsistent choices
- Absence of an explicit declaration of Python runtime version
- Too much to memorize when using bare tooling, with internal documentation too verbose
- Understanding how Python compiles dependencies is outside the skillset of most data scientists and many others
- Scripting may not scale appropriately
System Python Unreliable, Inflexible
My team uses macOS for development and deploys to Linux.
There is no system Python 3 in modern macOS. It's just a component that is installed as a part of Xcode. Previously, Apple shipped Python pre-installed. Apple said not to rely on this in the 10.15 release notes, indicating that it's for internal use only and would be removed. Apple then removed system Python in macOS 12.3, as warned in 10.15. Nowadays, Apple tends to keep its Xcode-provided Python 3.x installation within Python EOL dates but it can be a little out of date, as lst. 1 shows — the current version as of the end of August 2023 is 3.9.18.
This “for internal use only” is a policy similar to Homebrew’s but at least Homebrew’s Python won’t entirely disappear in a new OS release. That is, management of the system Python is out of the user's control because it is coupled with OS and core development tool updates.
This one is a bit of a given; nearly all Python developers with a project in production learn quickly not to develop against a macOS-provided Python.
Listing 1: The date, macOS version and arch, and Python version
$ date && sw_vers && uname -sm && /usr/bin/python3 --version Tue Jul 18 12:50:08 EDT 2023 ProductName: macOS ProductVersion: 13.4 BuildVersion: 22F66 Darwin arm64 Python 3.9.6 Inconsistent Installation Methods and Source
There are a ton of ways to install and use Python.
- Operating System-provided packaging?
- Homebrew?
- Pyenv? Anaconda?
- …MacPorts? …Nix?
My team was consistently bringing their own Python and installing it however they felt was most appropriate. This led to problems where team members were using newer language features, newer packages without backward compatibility, or older versions that were slower for testing, and we experienced a host of other problems that creep up when there’s no standard.
The solution was to align per-codebase on a particular version. However, this isn’t quite so easy. Using system-provided Python is inadvisable because it’ll change, and it’ll go away eventually. Using Homebrew Python is like hitting a moving target and is inadvisable, as Homebrew regards its Python as internal to Homebrew, similar to how Apple regards its Python installation. Using PyEnv or ASDF probably as correct as choosing Anaconda, which PythonSpeed reports was the most performant as of 3.9 but lost its advantage in 3.10, but both require knowledge of the tool and some setup. I’m sure there are still MacPorts holdouts somewhere and the rumblings of the Nix horde can be heard in the distance chanting “reproducible builds!”
It’s OK if you don’t know what any of these are because this developer experience in the end should abstract them away and do so on a per-repository basis with conventions established across teams.
Inconsistent Python Versions
So, we didn’t have clear single-source installation of our Pythons and we didn’t use versions consistently.
While many of our projects are tied to a particular version because of a hard requirement on our compute-centric big data cluster, we still had unexercised freedom to choose updated versions in other contexts, including containerized services and pipelines.
There also exists some risk from tech debt and bit rot when dependencies stop supporting older versions, or those older versions are end-of-life and unsafe to continue using.
- Python 3.7 and older, EOL
- Python 3.8, 3.9 in security-only phase
- EOLs Oct. 2024, Oct. 2025
- Python 3.10, 3.11, 3.12 supported
- Final non-security release in April: 2023 & 2024 & 2025
- EOL October: 2026 & 2027 & 2028
Long and Difficult to Remember Commands
No one can remember pip/poetry commands beyond the basics, or wants to type them or wants to use the correct, full-length command, e.g. poetry run pytest. Neither enables build actions outside of their domain. pipenv is no better.
pip — Package Installer for Python — is a venerable tool and, under the hood, even poetry (until Poetry v1.4) used pip. pipenv combines pip’s dependency management and package installation with automatic virtual environment management. poetry is a tool that combines a different approach to dependency management, virtual environment management, and package installation with package building and publishing.
pip was built in a time outside of configuration file conventions, and preferred to stick to its particular strength in the UNIX philosophy of doing one thing and doing it well. Its requirements.txt manifest is effectively a list of command line options.
The PEP 518 standard pyproject.toml really helps a lot but it takes some steps to get to development cycle usability. PEP 518 was accepted in 2016 and is commonly used in newer projects, but there are plenty of older codebases that may never move off setuptools, the original and still widely used way of defining packages and their dependencies using Python code executed at package build and installation time
All of these build steps are automatable. If a repo is not using poetry, or needs to use pip in an intermediary step, then it’s best to script these actions instead of executing them manually from a list in a README.
Python Ecosystem May Necessitate Compiling with Options
Pythonistas seem pretty accustomed to having packages “just work” when installed. Our team's Python dependency installation became complicated as Apple transitioned to its own processors using the ARM64 architecture. We had to support our developers' workstations using both that and the x86_64 architecture used in Apple's older Intel-based computers. The Python community, being largely volunteer open source maintainers, hadn't yet released en masse binary packages supporting the new platform. Some of our workstations are using Apple Silicon CPUs, while others are still Intel CPUs. Many Python packages used in data science have compiled binary libraries inside of them. Python has to retrieve the package that matches the system’s CPU architecture.
More than three years in, while many projects have released macOS ARM64 binary packages, some still have not. It’s FAR better than it was in 2021 and a lot better than 2022. There are many variables and barriers to this, notably the slim availability of macOS ARM64 continuous integration system runners capable of building the binaries. GitHub recently launched macOS ARM64 build worker availability, so this availability should improve greatly in the coming months. Nevertheless, it necessitates building some packages from the source distribution and that requires passing arguments or environment variables to Python packaging tools. As of January 2024, we compile few packages upon installation but retain the infrastructure necessary to do so just in case we need it.
For example, installing pyodbc on an ARM64 Mac requires passing compiler flags, which lst. 2 shows is not ergonomic.
Listing 2: Compiler flags necessary to install pyodbc on an ARM64 Mac
$ LDFLAGS="-L/opt/homebrew/Cellar/unixodbc/2.3.9_1/lib -lodbc -liodbc -liodbcinst -ldl" CPPFLAGS="-I/opt/homebrew/Cellar/unixodbc/2.3.9_1/include -I/usr/include" HDF5_DIR=/opt/homebrew/opt/hdf5 poetry install Moreover, how, outside of a README review, does a user know that they need to install the unixodbc package from Homebrew? Documentation is often left to READMEs, not tooling. We have tools to do this, like simple shell or Python scripting, right?
Scripts Grow Hard to Manage
We can write a bunch of scripts for this automation.
A collection of scripts that gets copied around is one way to solve this. Another way to is to have some shared repository of scripts that gets pulled in as a git submodule or installed as a separate Homebrew package. However, specialization for each particular consuming repo becomes difficult once shared. Files get copied around and eventually it’s a series of snowflakes: individual special build files.
Any sufficiently advanced system of one-off scripts eventually reimplements proper DAG — directed acyclic graph — build tool, so let’s just use one from the start.
The Remedy
We need a task runner for onboarding and resync instead of just better documentation.
This automation must install in approximately this order:
- whatever installs Python
- Python
- whatever installs Python dependencies’ dependencies
- whatever installs Python dependencies
- Python dependencies’ dependencies
- Python dependencies
- everything else needed somewhere in there
Let’s install Python and others from a package manager so we’re not bound to what the operating system vendor provides and so we’re all using the same versions, the same tooling, with the possibility for the same experience to build a common vocabulary and common procedures for developing and debugging our code.
Python Installation Methods
There are a ton of ways to install and use Python:
- Use the system-provided Python,
- install a minor version packages from Homebrew directly (with caveats about rolling updates; and don’t forget that a version switch is system-wide),
- install from Homebrew a runtime version manager such as pyenv or asdf that can install specific minor or patch version and easily switch per-directory,
- or install from Homebrew another, specialized package manager such as Anaconda that can install optimized Python builds in an environment activated per-project or per-directory.
I found that our team tended to choose Homebrew or Conda Python when left to their own devices, myself included prior to understanding the ramifications of that. So, I made a graph, fig. 1, to understand the possibilities.
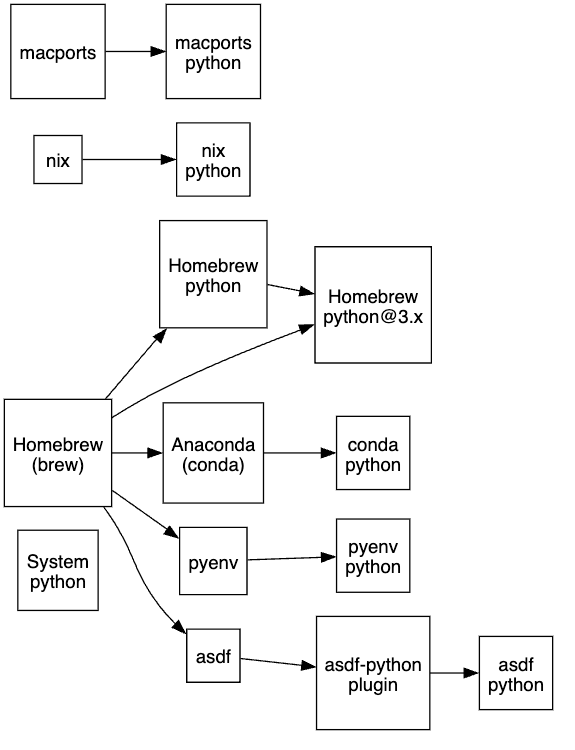
Figure 1: Python installation methods (diagram created internally)
Once I made this graph, I realized it looked familiar. Turns out, XKCD comic #1987 described this problem more than 10 years ago!
Again: Which Python?
So, we return to this central question with a clear way forward: explicitly say which version and provide a mindless way to install it. Treat it just like any other dependency, like some other ecosystems do [1]. ([1] Notably, Scala, because the Scala runtime is just another library to the Java Virtual Machine.)
Essentially, when we ask
“Which Python?”
we are now able to responsibly answer,
“This one, and you need not care how it comes to be available.”
Homebrew + Pyenv
Homebrew as a base requirement is safe for us as we’re primarily on Macs or Linux.
I have contributed to Homebrew for more than a decade and currently serve on its Project Leadership Committee.
I chose pyenv because it seemed to be the lowest barrier to entry to get the exact version of Python we needed and avoid it changing from underneath the developer when running updates. We deemed it acceptable to have to recompile, if necessary, because pyenv could handle the dependency installation through Homebrew, the availability of which we already assumed.
At introduction, I allowed for the user to have Conda or Homebrew-managed Pythons active because I didn’t want to break existing setups without a clear need to do so. Our choice of text editor or IDE was open, and I wanted to support that. Over time, as this system matured, the need for these went away. We also converged on using PyCharm or another Jetbrains IDE, Visual Studio Code, or Vim for editing. We use Brewfile to declare any other program or dependencies we need and Peru as a generic package manager for retrieving test data. Fig. 2 shows what we did.
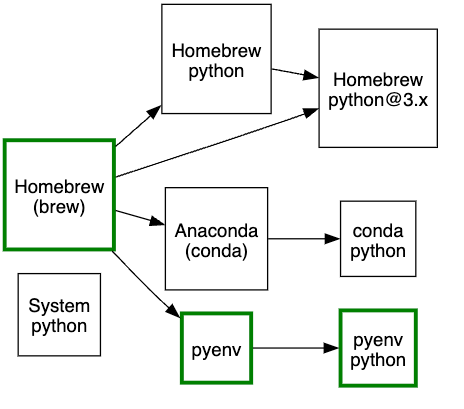
Figure 2: Our Python installation method (diagram created internally)
Poetry for Python dependencies and packaging
I quickly settled on Poetry for dependency management, packaging, and publishing as many new Python projects seem to be gravitating toward it or Pipenv. Nearly all Python tooling projects are committed to supporting the PEP 518 pyproject.toml format. We continue to watch the development of other tools in the space but are heavily invested in Poetry now.
The Python ecosystem uses virtual environments, known as virtualenvs or venvs, to isolate sets of dependencies by creating a separate directory hierarchy for each set. Poetry’s own installer smartly manages a separate virtualenv, avoiding a pesky problem where evicting dependencies not in an app’s dependency tree can break Poetry or other similar tools.
Since Poetry combines dependency management, packaging, and publishing into one smart tool, we avoid the problem of having to know or automate many tools. We have one tool that does all that we need, with the freedom to use something else via a crisp abstraction we’ve built on top of it in our Makefile.
Installing Poetry
There are also a ton of ways to install Poetry. The Poetry maintainers strongly encourage using their installer or pipx. While it can be installed via Homebrew or via pip, upstream does not support a brewed poetry. Additionally, they warn that a pip-installed Poetry may create version conflicts. We have encountered this problem and hobbled Poetry in the process.
The Poetry maintainers instruct users to install with the official installer or pipx to provide automatic and reliable virtual environment isolation. Poetry does not need to be installed inside a codebase’s active virtualenv. Rather, it manages it externally. So, when we install Poetry, it uses whatever Python 3.x is available because it’s probably safe to do so. In our setup, it usually ends up using a Homebrew-provided Python because of how our setup ends up building the shell PATH environment variable. Fig. 3 shows this.
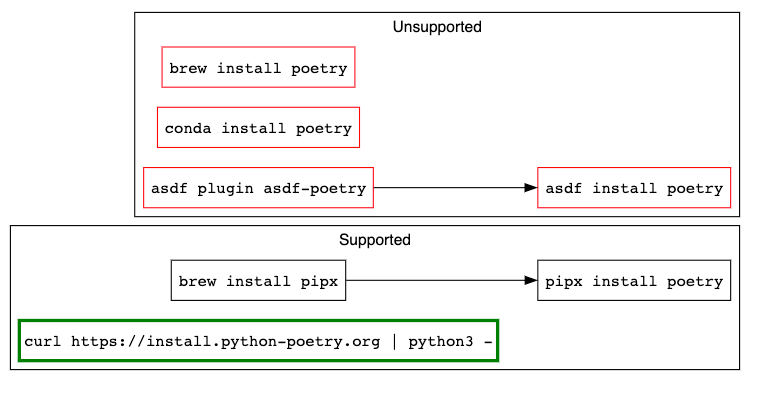
Figure 3: Poetry Installation; Green is recommended, black is acceptable, red is undesirable (diagram created internally)
Poetry runs in its own virtualenv and creates a virtualenv for the codebase, as fig. 4 shows. The user can instruct Poetry which python executable to use when creating the virtualenv.
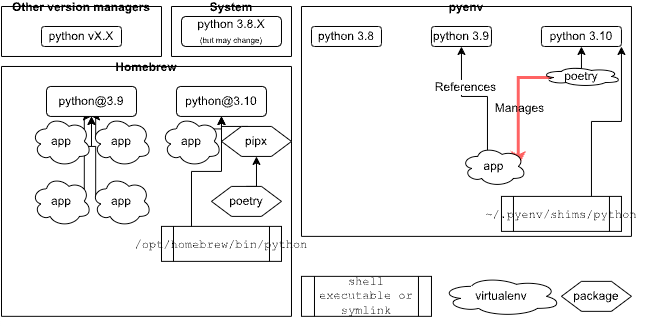
Figure 4: Installed Poetry uses its own virtualenv and manages other virtualenvs externally (diagram created internally)
Rejected Solutions
I rejected a few commonly suggested solutions out of productivity concerns. The ideal solution would keep development iterations as quick as possible and encourage test-driven development to produce high-quality software.
- Containers - too slow, IDE problems
- Develop on cluster - wildly slow, IDE problems
- Rewrite in another language or ecosystem - Complexity not worth considering
Glue
But I needed some glue to make all of this automated from some common tooling. I need the greatest common denominator. Make.
A full Make tutorial is out of scope for this article. Make is older than The Internet, with its first version coming out in April 1976. There is plenty of material out there on it such as MakefileTutorial.com.
Standardized Makefile for Python + Shell dev
I’ve long used a minimal Make setup in every ecosystem to provide a common onboarding experience, be it a Java project using maven or gradle, an SBT project for Scala, or projects in Ruby, Rust, Groovy, or a variety of other ecosystems I’ve worked in, all with varying maturity of their build system and dependency retrieval tooling.
Make is widely available and built into macOS, or at least enough of a standard Make installation to be useful. We can build a Makefile, the configuration file for the program, that we can pretty easily share safely across most Python projects. Lastly, instead of invoking particular tools specifically in CI, we can execute Make tasks and allow that repo to have its own configuration for running. That way, we can strike the right balance of convention and configuration.
make learn-make
Basic Task Runner
Lst. 3 shows the most basic usage of Make. With this, you can run make task and command will run. It will run every time you invoke it. You may see .PHONY near this: that simply declares that the task will never produce a file and should be executed every time it is encountered in the task DAG[2]. ([2] Directed acyclic graph)
Listing 3: A theoretical example Makefile
task: dependency-task ## Helpful explanation of the task ↦ command --that does --something ↦ = tab Lst. 4 shows something you can try right now if you have Make installed already. Write its contents to a file, and then run make, then make hello, and make goodbye.
Listing 4: A hello world Makefile
hello: echo "Hello world!" goodbye: hello echo "Goodbye, world!"Observe the behavior of each — in lst. 5 — and realize that Make runs
- the first listed task when no tasks are passed to the command (make)
- the desired task when passed (make hello)
- the tasks on which the desired task depends before the desired task (make goodbye)
Listing 5: The output of the hello world Makefile
$ make echo "Hello world!" Hello world! $ make hello echo "Hello world!" Hello world! $ make goodbye echo "Hello world!" Hello world! echo "Goodbye, world!" Goodbye, world! Produce Files
The other basic use case for Make is to produce files. Originally, Make was intended to compile source files and is still widely used in especially C and C++ projects for that purpose. I’ve even used Make to compile Java projects long ago.
In lst. 6, you can see that the output file has a task that depends on an input file. That input file could have a task of its own, but Make can figure that out pretty well. In this invocation, I’ve used some Make variables dereferencing the output and input, respectively.
Listing 6: A real example Makefile
build: output.txt output.pdf ## Build the things output.txt: input.txt ↦ command --that produces --something $@ --from $< make build will only run the output.txt task when:
- output.txt doesn’t exist
- input.txt has changed since the last time the task was run
Why Not X?
Why not something else?
- CMake
- Gradle
- SBT
- XMake
- Just
- OK
- Meson
- Brazil
- npm
- Maven
- Ant
- Rake
- scons
- ninja
- rad
I’ve used probably two-thirds of these, and they’re great for a particular ecosystem, but literally none beat the ubiquity of Make.
When developer experience is the primary focus, using what the developer already has available to bootstrap the rest is very important. It’s very easy to install one of the above tools should a codebase necessitate it, but having a Makefile that bootstraps that installation is nigh unavoidable.
The Ideal Tasks
One command should enable a developer to move from a fresh copy of the source code into a productive state having assured that their workstation, their development environment, and the source code itself is ready for work:
make deps check test build This can and should be reduced to a single step:
make all And because all can be the first or default task, simply:
make Four keys, plus Enter, and a developer is ready to work. That’s the ideal onboarding experience.
Many years ago, at a leading cloud platform as a service, a principal engineer instituted a policy of requiring a Makefile with these four steps in every codebase, even if all deps did was to install another build tool and all the other three did was to run that build tool’s similarly-named tasks. Some others surfaced over time that made sense, too.
make help # displays tasks available make clean # restores to a pristine state This had the effect of ensuring a clean onboarding process for anyone who may come along working on a project. It was a great success for developers unfamiliar with a particular ecosystem’s tools and enabled productivity nearly immediately: clone the repo, then run make. Wait a few minutes. Then you’re in a red-green-refactor test-driven development cycle with tooling virtually guaranteed to work.
This inclusivity is a key part of a healthy engineering culture. I’m adamant about good developer experience, and this particular way of realizing it is a time-tested method that continually proves its value quickly once implemented.
Our Particular Setup
A while ago, I came upon an excellent help generator task that I’ve now used just about everywhere. This enables a self-documenting Makefile with a helpful output: no reading of a Makefile required to understand what the tasks do while keeping the task names typeable.
$ make help Usage: make Utility help Display this help version-python Echos the version of Python in use Use the code in lst. 7 if you want to use this excellent task in your Makefile.
Listing 7: A great task for generating make help
##@ Utility .PHONY: help help: ## Display this help @awk 'BEGIN {FS = ":.*##"; printf "\033[1m\nUsage\n \033[1;92m make\033[0;36m <target>\033[0m\n"} /^[a-zA-Z0-9_-]+:.*?##/ { printf " \033[36m%-15s\033[0m %s\n", $$1, $$2 } /^##@/ { printf "\n\033[1m%s\033[0m\n", substr($$0, 5) } ' $(MAKEFILE_LIST) ##@ Section Header taskname: ## Tasks with TWO '#' will have descriptions when running 'make help' With one command, make deps, the whole cornucopia of software necessary to work on the codebase gets installed. Libraries from Homebrew, Pyenv, Python, Poetry, all Python dependencies, everything. If we need to re-run one of these steps, we can run it without running the other things.
Dependency Setup deps Installs all dependencies deps-brew Installs dev dependencies from Homebrew deps-peru Installs data dependencies using Peru deps-py Installs Python dev and runtime deps deps-py-update Update Poetry deps We use Peru to retrieve some large files used in testing. It’s a great ecosystem-agnostic dependency retriever as an alternative to git submodules or a script that dumbly recopies data.
We can run tests with a simple make test. We can also tell Poetry to build a wheel and sdist, and publish them to our internal PyPI repository.
Testing test Runs tests Building and Publishing build Runs a build publish Publish a build to the configured repo And we have plenty of code quality checks. We love flake8, black, mypy, and more that enable us to write maintainable code that captures our intent.
Code Quality check Runs linters and other important tools check-py Checks only Python files check-py-flake8 Runs flake8 linter check-py-black Runs black in check mode (no changes) check-py-mypy Runs mypy check-py-ruff Runs ruff (beta) check-sh Run shellcheck on shell scripts fix-sh Runs shellcheck and applies suggestions format-py Runs black, makes changes where necessary format-shell Runs shfmt on all shell scripts and tests Challenges
This was not without some challenges to set up, as I will detail below.
Supporting Multiarchitecture
There’s still a small but necessary challenge to support both Apple Silicon’s ARM architecture for the M-series CPUs and GPUs and the legacy Intel architecture for our engineers and data scientists. We must support macOS x86_64 & arm64 for development and Linux x86_64 for production, where we’re running our model training on high-end GPUs from Nvidia.
The Python package ecosystem is increasingly shipping binaries for ARM Macs, but I still have to compile some dependencies from source, because, in a lot of cases, Python is merely a nice wrapper around a library written in a compiled language like C, C++, or Rust. Things are better in Python 3.11 so far, but the ecosystem hasn’t fully caught up yet with the recent release.
Lst. 8 shows an example of how we set compiler flags needed to successfully install two of our Python dependencies which did not, may still not, and may never have had binaries compiled for all of our supported platforms.
Listing 8: Example of setting compiler flags
FLAGS = ifeq ($(shell uname -m), arm64) ifeq ($(shell uname -s), Darwin) HDF5_DIR = $(shell brew --prefix --installed hdf5) LIBS = odbc libiodbc F_LDFLAGS = LDFLAGS="$(shell pkg-config --libs $(LIBS))" F_CPPFLAGS = CPPFLAGS="$(shell pkg-config --cflags $(LIBS))" FLAGS = $(F_LDFLAGS) $(F_CPPFLAGS) HDF5_DIR="$(HDF5_DIR)" endif endif POETRY = $(FLAGS) poetry You’ll probably see this in just about every Makefile that necessitates setting compilation flags for Poetry to use. Here, I’m referencing dependencies needed by pyodbc and hdf5, which for the foreseeable future necessitate compilation from source to install on an ARM64 Mac.
Note that uname -m outputs the microarchiture, which is arm64 and that uname -s outputs the system name, which is Darwin, the actual system name for macOS. The rest of the commands inside this block run Homebrew and a standard tool called pkg-config to get the location of the libraries that Homebrew installed. It’d be great if hdf5 followed pkg-config conventions, but it doesn’t so here we are.
Lst. 9 and lst. 10 show what the actual poetry command will look like in various scenarios.
Listing 9: The Poetry command executed on macOS ARM64, with compiler flags.
LDFLAGS="-L/opt/homebrew/Cellar/unixodbc/lib -lodbc -libiodbc" \ CPPFLAGS="-I/opt/homebrew/Cellar/unixodbc/include" \ HDF5_DIR="/opt/homebrew/Cellar/hdf5" poetry Listing 10: The Poetry command executed on macOS x86_64 or Linux; no compiler flags.
poetry
Drawbacks
This approach is not without some technical drawbacks, most of which are inconveniences.
Distributing Makefile updates is challenging. When we want to make a small change that affects all of the Makefiles, we need a developer to do that. We could automate many changes in this category with a combination of tools such as fastmod to effect Makefile changes and the GitHub CLI gh tool to submit the oodles of pull requests. It can be tempting to script the generation of a Makefile, perhaps starting from a basic one then including one generated after retrieving some base template, but we have avoided that complexity thus far.
We identified template drift as a risk. Some aspects of our Makefiles are specialized to a repository’s codebase. When we create a new project codebase from our template, we have to change a few values. While we’d like to think that we’ve extracted those changing values to variables, we are human and miss things sometimes. Also, when a developer makes a change to the Makefile, the change might not be in the same place in every Makefile. So, over time, a repository’s Makefile eventually drifts from the template. This difference could complicate automated changes.
The last technical drawback worth calling out specifically is the difference between Make implementations. macOS ships with a 2006 version of GNU Make while nearly all Linux distributions and Homebrew ship a very recent GNU Make. GNU Make is easily installable through Homebrew on macOS, though. We write for the older Make, because it is stricter. There are subtle differences between the two: it’s worth saying that there are, but finding an up-to-date article that clarifies the differences is an exercise left to you, reader.
A drawback worth identifying that is non-technical is that Make is another technology to learn. The body of a Make task is effectively a script which Make can alter on the fly. Each Make task could be a separate script file, but Make really shines when there is a chain of dependencies: set a task list instead of running a script that runs a bunch of scripts, and let Make figure out the order and manage the concurrency. It takes time to learn this tool, but the first step is nearly always easier than resorting to a collection of scripts the complexity of which grows unbounded.
Future Work
This was hopefully enough to catch your interest and spark conversation for your Python team, or any team struggling to quickly onboard developers to new codebases, or codebases they’ve not touched in many months.
I have no doubt this system will improve over time, but on its third major iteration in three years and openly talking about it inside and outside of Target, and contributing to several Python open source projects in that time, it’s clear that something like this is needed in some form for nearly all Python projects.
I’m aware of some great new tools in the Python developer experience arena, such as uv, and look forward to trying them out as they mature.
Improvements
We’re working on some other improvements, especially as my current team of around a dozen developers adopted this setup for all of its primarily Python repos. We’ve adopted it for 100% of our projects and I have had no complaints that were not immediately addressable.
The greatest challenge we’ve encountered so far in rolling this out is some of the one-time setup that’s required to tell package managers like Homebrew, Pyenv, Poetry, and more where to look for executables. Some of it can be automated but such often frustrates those who manage their dotfiles carefully, including myself.
If you use zsh, which is the default in macOS 11+, you could drop lst. 11 into ~/.zprofile to skip all of the headaches we’ve encountered.
Listing 11: .zprofile enabling usage of our tooling
# Enables Homebrew when present BREW_LINUX=/home/linuxbrew/.linuxbrew/bin/brew BREW_MAC_ARM=/opt/homebrew/bin/brew BREW_MAC_X86=/usr/local/bin/brew if [ -f $BREW_MAC_ARM ]; then eval "$($BREW_MAC_ARM shellenv)" elif [ -f $BREW_MAC_X86 ]; then eval "$($BREW_MAC_X86 shellenv)" elif [ -f "$BREW_LINUX" ]; then eval "$($BREW_LINUX shellenv)" fi # Enables pyenv when present if command -v pyenv > /dev/null; then eval "$(pyenv init --path)" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)" || true fi # allow commands installed here, such as poetry export PATH="$HOME/.local/bin:$PATH" We’ve seen some troubleshooting complexity for folks with older setups. Cruft and configuration accumulate over time and many tools encourage putting things into shell configuration such as ~/.zprofile or ~/.bash_profile without the user actually knowing what it does. We wanted not to mess up working setups, so we moved more and more toward a stricter environment setup as time goes on until we’re confident not only in our tooling but also in our ability to use the tooling and understand how to approach fixing it. That is, we’re more opinionated on where something gets installed so we can easily reference from our shiny setup while minimizing the work that a developer needs to do for one time setup, e.g. putting things into their shell configuration files.
Outcomes and Conclusion
This Makefile configuration delivered remedies for all of the pain points of what we were doing prior to its implementation.
- We know which Python version a project should use, avoiding confusion.
- We know which Python vendor from which to install Python, avoiding behavioral quirks.
- Python installation is automated, avoiding manual work.
- Python dependency installation is automated, along with installing any dependencies outside of the Python ecosystem and ensuring they are properly referenced where needed. This drastically reduces confusion and workarounds, especially during a time of microarchitecture transitions.
- We have a task runner that defines and executes many other helpful development tasks. This avoids work duplication while enabling knowledge sharing previously unexercised.
The crowning achievement of this setup — the moment we knew it was worth it — was during the first time we enlisted someone new to our codebases to help us resolve a challenging problem in the code itself. They, a veteran engineer with little recent Python experience, were able to transition from “no Python tooling installed” to “checks and tests passing” in four commands with nothing relevant to our codebase pre-installed other than Homebrew:
- git clone ${CODE_URL} to get the code.
- make deps to install the basic dependencies.
- A one-time setup task, e.g. placing the contents of lst. 9 where it needs to be to load Homebrew and pyenv. The output of the above command tells the user what to do.
- make deps to finish dependency setup using what the previous task enabled.
- make check test to run checks and tests.
Since then, we’ve onboarded others who have also commented how streamlined this setup is. I’ve shared this in presentation form at conferences and local developer meetings with much praise.
I hope this helps you and your team, inside your company or in the open source community, find a solution to the problems that you are having. If nothing else, I hope it helps you think about the onboarding developer experience in a new way, and set you on a course to think and act with inclusivity in mind.
A Complete Example
We’ve launched a complete example project at https://github.com/target/make-python-devex. The only prerequisites match our standard macOS development environment: Homebrew. Run make install-homebrew after cloning this repo and follow prompts, or follow the install instructions at Homebrew’s website.
Once these files are in place, you’ll
- run make deps until it exits successfully, following prompts with each failure
- run make deps check test build ARTIFACT_VERSION=0.0.1 to see all deps installed, checks and test pass, and produce a build in the dist directory.
- run poetry run example-make-python-devex to actually see what the program does.
If this all went right, you’ll see something like lst. 19 when you’re done.
Listing 19: Example project output
$ poetry run example-make-python-devex 2023-07-18 17:26:36.057 | INFO | example:main:8 - Starting 2023-07-18 17:26:36.057 | DEBUG | example:do_something:16 - Doing something! 2023-07-18 17:26:36.057 | INFO | example:<lambda>:12 - Exiting! Note: This solution is in active use and continuous development, so some things might have changed since this article was published. This system matures frequently despite being in use for more than two years. While writing this post, someone suggested a minor change to the make help task for the first time in years; it was such a great improvement that we quickly incorporated it into all of our Makefiles.
RELATED POSTS
Requirements for Creating a Documentation Workflow Loved by Both Data Scientists and Engineers
By Colin Dean, April 6, 2022
This is an adaptation of a presentation delivered to conferences including Write the Docs Portland 2020, Ohio Linuxfest OpenLibreFree 2020, and FOSDEM 2021. The presentation source is available at GitHub and recordings are available on YouTube. This is a two-part post that will share both the requirements and execution of the documentation workflow we built that is now used by many of our teammates and leaders. Read part two here.
Executing a Documentation Workflow
By Colin Dean, April 6, 2022
This post is the second in a two-part series about creating a documentation workflow for data scientists and engineers. Click here to read the first post. This is an adaptation of a presentation delivered to conferences including Write the Docs Portland 2020, Ohio Linuxfest OpenLibreFree 2020, and FOSDEM 2021. The presentation source is available at GitHub and recordings are available on YouTube.